Commonsense knowledge graph can be useful source of explicit knowledge for generating texts that make sense. However, it is hard to use KG since it would hold huge amount of information than needed. Retrieving graphs which is relevent for the generation is the key.
Though knowledge graph can capture the essence of corpus, generating sentences based on the graph is difficult task. This paper tried to generate texts(paper abstracts) from KG in science(AI) domain.
Knowledge graph is graph representation of knowledge. Entities are represented as nodes and relations between entities are represented as edges. Commonsense knowledge graph stores commonsense knowledge in form of graphs. Two of common dataset for commonsense knowledge graph are ATOMIC and ConceptNet.
There were some problems in previous VQA dataset. Strong language prior, non-compositional language and variablility in language were key obstacles for model to learn proper concepts and logics from VQA dataset. Synthetically generated CLEVR dataset solved these problems to some extent but lacked realisticity by remaining in relatively simple domain.
Information retrieval from search engine becomes difficult when the query is incomplete or too complex. This paper suggests a query reformulation system that rewrite the query to maximize the probability of relevant documents returned.
Former neural module network for VQA depends on a naive semantic parser to unroll the layout of the network. This paper suggests End-to-End Module Networks(N2NMN) to directly learn the layout from the data.
This paper describe several tips and tricks for VQA challenge with the first place model in 2017 VQA challenge. Also, this paper conducts comprehensive experiment for ablation of each trick.
AQM solves visual dialogue tasks with information theoratic approach. However, the information gain by each candidate question needs to be calculated explicitly which leads to lack of scalability. This paper suggests AQM+ to solve large-scale problem.
Goal-oriented dialogue tasks require two agents(a questioner and an answerer) to communicate to solve the task. Previous supervised learning or reinforcement learning approaches struggled to make appropriate question due to the complexity of forming a sentence. This paper suggests information theoretic approach to solve this task.
Former methods used element-wise sum, product or concatenation to represent the relation of two vectors. Bilinear model(outer prodct) of two vectors is more sophisticated way of representing relation, but usually dimensionality become too big. This paper suggests multimodal compact bilinear pooling(MCB) to represent compact and sophisticated relations.
Previous methods for visual reasoning lacked interpretability. This paper suggests MAC network which is fully differentiable and interpretable attention based visual reasoning model.
Previous works achieved successful results in VQA by modeling visual attention. This paper suggests co-attention model for VQA to pay attention to both images (where to look) and words (what words to listen to).
While bilinear model is an effective method for capturing the relationship between two spaces, often the number of parameters is intractable. This paper suggests to reduce the number of parameters by controlling the rank of the matrix with Turker decomposition.
Spatial sampling of convolutional neural network is geometrically fixed. This paper suggests two modules for CNN to capture the geometric structure more flexibly.
Recent neural network models are getting bigger to increase the performance to the limit. This paper suggests MobileNet to reduce the size of neural network small enough to deploy on mobile devices.
Recent neural network models are getting bigger to increase the performance to the limit. This paper suggests MobileNet to reduce the size of neural network small enough to deploy on mobile devices.
Image segmentation requires a lot of annotated images. This paper suggests efficient training of image segmentation using data augmentation and new structure.
High quality disentangled generation of images has been the goal for all the generative models. This paper suggests style-based generator architecture for GAN with techniques borrowed from the field of style transfer.
Generating a high resolution image with GAN is difficult despite of recent advances. This paper suggests BigGAN which adds few tricks on previous model to generate large scale images without progressively growing the network.
Representing bilinear relationship of two inputs is expensive. MLB efficiently reduced the number of parameters by substituting bilinear operation with Hadamard product operation. This paper extends this idea to capture bilinear attention between two multi-channel inputs.
Using external memory as modern computer enable neural net the use of extensible memory. This paper suggests Differentible Neural Computer(DNC) which is an advanced version of Neural Turing Machine.
Using external memory as modern computer enable neural net the use of extensible memory. This paper suggests Differentible Neural Computer(DNC) which is an advanced version of Neural Turing Machine.
Object box proposal process is complicated and slow in object detection process. This paper proposes Single Shot Detector(SSD) to detect objects with single neural network.
Constructing 3D shape from a single image is challenging. Training end-to-end to predict 3D shape from 2D image often end up overfitting while not generalizing well to other shapes.
Constructing 3D shape from a single image is challenging. Training end-to-end to predict 3D shape from 2D image often end up overfitting while not generalizing well to other shapes.
Relational Network showed great performance in relational reasoning, but calculations and memory consumption grow quadratically with the number of the objects due to fully connected pairing process.
Skip-Gram Negative Sampling(SGNS) showed amazing performance compared to traditional word embedding methods. However, it was not clear where SGNS converge to.
Word embedding using neural network(Skipgram) seems to outperform traditional count-based distributional model. However, this paper points out that current superiority of word2vec is not because of the algorithm itself, but because of system design choices and hyperparameter optimizations.
Bilinear model can caputure rich relation of two vectors. However, the computational complexity of bilinear model is huge due to its high dimensionality. To make bilinear model more applicable, this paper suggests low-rank bilinear pooling using Hadamard product.
Bilinear model can caputure rich relation of two vectors. However, the computational complexity of bilinear model is huge due to its high dimensionality. To make bilinear model more applicable, this paper suggests low-rank bilinear pooling using Hadamard product.
Visual question answering task is answering natural language questions based on images. To solve questions that require multi-step reasoning, stacked attention networks(SANs) stacks several layers of attention on parts of images based on query.
Visual question answering task is answering natural language questions based on images. To solve questions that require multi-step reasoning, stacked attention networks(SANs) stacks several layers of attention on parts of images based on query.
Visual question answering task is to answer to natural language question based on images requiring extraction of information from both images and texts. Stacked Attention Networks(SAN) stacked several layers of attention to answer to complicated questions that requires reasoning. Multimodal Residual Network (MRN) points out weighted averaging of attention layers in SAN works as a bottleneck restricting the information of interaction between questions and images.
Visual question answering task is to answer to natural language question based on images requiring extraction of information from both images and texts. Stacked Attention Networks(SAN) stacked several layers of attention to answer to complicated questions that requires reasoning. Multimodal Residual Network (MRN) points out weighted averaging of attention layers in SAN works as a bottleneck restricting the information of interaction between questions and images.
While conventional deep learning models have performed well on inference regarding individual entities, few models have been proposed focusing on inference regarding the relations among entities. Relational network aimed to capture relational information from images. In this paper, relational recurrent neural network tried to improve former memory augmented neural network models to capture relations among memories.
While conventional deep learning models have performed well on inference regarding individual entities, few models have been proposed focusing on inference regarding the relations among entities. Relational network aimed to capture relational information from images. In this paper, relational recurrent neural network tried to improve former memory augmented neural network models to capture relations among memories.
For audio source separation task, traditional approach only utilized magnitude part ignoring phase part. Previously deep complex network provided complex arithmetics via convolution.
Autoregressive model has been dominant model for density estimation. On the other hand, various non-linear transformations techniques enabled tracking of density after transformation of variables. Transformation Autoregressive Networks(TAN) combined non-linear transformation into autoregressive model to capture more complicated density of data.
Two approximation methods, Variational inference and MCMC, have different advantages: usually, variational inference is fast while MCMC is more accurate.
Gaussian process has several advantages. Based on robust statistical assumptions, GP does not require expensive training phase and can represent uncertainty of unobserved areas. However, HP is computationally expensive. Neural process tried to combine the best of Gaussian process and neural network.
Gaussian process has several advantages. Based on robust statistical assumptions, GP does not require expensive training phase and can represent uncertainty of unobserved areas. However, HP is computationally expensive. Neural process tried to combine the best of Gaussian process and neural network.
Generative models of discrete data with particular structure (grammar) often result invalid outputs. Grammar Variational Autoencoder(GVAE) forces the decoder of VAE to result only valid outputs.
Gradient descent methods depend on the first order gradient of a loss function wrt parameters. However, the second order gradient(Hessian) is often neglected.
Gradient descent methods depend on the first order gradient of a loss function wrt parameters. However, the second order gradient(Hessian) is often neglected.
Recent variational training requires sampling of the variational posterior to estimate gradient. NVIL estimator suggest a method to estimate the gradient of the loss function wrt parameters. Since score function estimator is known to have high variance, baseline is used as variance reduction technique. However, this technique is insufficient to reduce variance in multi-sample setting as in IWAE.
Efficient exploration of agent in reinforcement learning is an important issue. Conventional exploration heuristics includes \epsilon-greedy for DQN and entropy reward for A3C.
Batch normalization is known as a good method to stablize the optimization of neural network by reducing internal covariate shift. However, batch normalization inheritantly depends on minibatch which impeding the use in recurrent models.
Batch normalization is known as a good method to stablize the optimization of neural network by reducing internal covariate shift. However, batch normalization inheritantly depends on minibatch which impeding the use in recurrent models.
The largest drawback of training Generative Adversarial Network (GAN) is its instability. Especially, the power of discriminator greatly affect the performance of GAN. This paper suggests to weaken the discriminator by restricting the functional space of it to stablize the training.
Estimating the distribution of data can help solving various predictive taskes. Approximately three approaches are available: Directed graphical models, undirected graphical models, and density estimation using autoregressive models and feed-forward neural network (NADE).
All the previous neural machine translators are based on word-level translation. Word-level translators has critical problem of out-of-vocabulary error.
Modeling data with known probability distribution has a lot of advantages. We can exactly calculate the log likelihood of the data and easily sample new data from distribution. However, finding tractable transformation of data into probability distribution or vice versa is difficult. For instance, a neural encoder is a common way to transform data but its log-likelihood is known to be intractable and another separately trained decoder is required to sample data.
Reparameterization trick is a useful technique for estimating gradient for loss function with stochastic variables. While score function extimators suffer from great variance, RT enable the gradient to be estimated with pathwise derivatives. Even though reparameterization trick can be applied to various kinds of random variables enabling backpropagation, it has not been applicable to discrete random variables.
Reparameterization trick is a useful technique for estimating gradient for loss function with stochastic variables. While score function extimators suffer from great variance, RT enable the gradient to be estimated with pathwise derivatives. Even though reparameterization trick can be applied to various kinds of random variables enabling backpropagation, it has not been applicable to discrete random variables.
While the effect of batch normalization was widely proven empirically, the exact mechanism of it is yet been understood. Commonly known explanation for this was internal covariance shift(ICS) meaning the change in the distribution of layer inputs caused by updates to the preceeding layers.
While the effect of batch normalization was widely proven empirically, the exact mechanism of it is yet been understood. Commonly known explanation for this was internal covariance shift(ICS) meaning the change in the distribution of layer inputs caused by updates to the preceeding layers.
Instead of instantly responding to incoming stimulus, having a model of environment to make some level of prediction would help perform in reinforcement learning.
Gorila framework separated several actors and learners with a centralized parameter server to parrallelize the learning process. This framework required one GPU per learner.
Hierarchical recurrent encoder-decoder model(HRED) that aims to capture hierarchical structure of sequential data tends to fail because model is encouraged to capture only local structure and LSTM often has vanishing gradient effect.
In many enviroments of RL, rewards tend to be delayed from the actions taken. This paper proved that delayed reward exponentially increase the time of conversion in TD, and exponentially increase the variance in MC estimates.
Most of deep directed latent variable models including VAE try to maximize the marginal likelihood by maximizing the Evidence Lower Bound(ELBO). However, marginal likelihood is not sufficient to represent the performance of the model.
Traditional explanation for generalization of a machine learning model was primarily concerned with tradeoff between model capacity and overfitting. If capacity of a model is too large, you must contrain the capacity to prevent overfitting. Choosing appropriate level of capacity of model has been seen as a key to generalized performance.
Traditional explanation for generalization of a machine learning model was primarily concerned with tradeoff between model capacity and overfitting. If capacity of a model is too large, you must contrain the capacity to prevent overfitting. Choosing appropriate level of capacity of model has been seen as a key to generalized performance.
Feature learning in Convolution Neural Network requires many hand labeled data. It would be useful if one can use other form of supervision. In nature world, organisms acquire many essential information regarding vision by moving itself(egomotion).
In VAE framework, the quality of the generation relies on the expressiveness of inference model. Restricting hidden variables to Gaussian distribution with KL divergence limits the expressiveness of the model.
기존의 Turing Machine, 혹은 Von Neumann architecture 구조를 가진 컴퓨터들은 elementary operations, logical flow control, external memory라는 근본 메커니즘을 가진다. 기존의 machine learning 기법들은 이 세가지 메커니즘 중 첫번째에 집중해왔다. 최근 나온 RNN구조는 Turing complete하여 이를 활용하여 Neural Truing Machine을 만들 수 있다. 기존 Turing machine과는 다르게 NTM은 gradient descent로 학습이 가능하다.
기존의 Turing Machine, 혹은 Von Neumann architecture 구조를 가진 컴퓨터들은 elementary operations, logical flow control, external memory라는 근본 메커니즘을 가진다. 기존의 machine learning 기법들은 이 세가지 메커니즘 중 첫번째에 집중해왔다. 최근 나온 RNN구조는 Turing complete하여 이를 활용하여 Neural Truing Machine을 만들 수 있다. 기존 Turing machine과는 다르게 NTM은 gradient descent로 학습이 가능하다.
VAE의 구조의 latent variable을 사용하여 sequence를 reconstruct하려는 시도는 많았다. 하지만 decoder가 너무 강력해서 latent variable을 무시하는 ‘Posterior Collapse’현상이 많이 일어나서 긴 sequence의 정보를 가진 latent variable을 구성하긴 힘들었다.
NN모델들은 이미지를 인식/분류할 때 계층적 특징들을 학습한다. 하지만 Generative model들은 계층적으로 생성하지 않는다. Stacked Hierarchy를 가지고 있는 HVAE(Hierarchical VAE)같은 경우는 계층적인 구조를 가지고 있지만 각 층이 계층적인 특징을 학습하지 못한다. 마지막 층(Bottom layer)에 정보가 충분하여 마지막 층만 사용하여 이미지를 reconstruct할 수 있다. 하지만 마지막 층만 사용한다면 unimodal하기 때문에 multimodal한 구조를 잡지 못하고 특징들은 disentangle되지 못한다.
consciousness를 특정 순간의 awareness라고 한다면 여러 저차원 concept들의 조합이라고 생각할 수 있다. 이러한 저차원 개념(thought vector)들은 현실에 대한 사실이거나 결정을 내리는데 유용한 명제(statement)로 구성될 수 있다. 이러한 의식을 통하여 미래에 대한 예측을 하고 의사결정을 내릴 수 있다. 기존에는 감각으로 부터 오는 데이터(sensory data)로 부터 직접 의사결정을 한다고 간주되어 왔지만 consciousness prior는 agent가 고층위 abstract space에서 예측 및 의사결정을 내릴 수 있게 해준다. 이러한 conciousness prior는 복잡한 의식으로 부터 단순화된 언어를 통하여 표현하는 자연어 발화 과정에도 부합한다. consciousnes는 agent가 현재에 유용한 표현을 만들기 위하여 abstract concept들 중에서 몇몇의 concept에 주목하여 구성된다는 점에서 착안하여 attentive awareness 라고도 볼 수 있다.
consciousness를 특정 순간의 awareness라고 한다면 여러 저차원 concept들의 조합이라고 생각할 수 있다. 이러한 저차원 개념(thought vector)들은 현실에 대한 사실이거나 결정을 내리는데 유용한 명제(statement)로 구성될 수 있다. 이러한 의식을 통하여 미래에 대한 예측을 하고 의사결정을 내릴 수 있다. 기존에는 감각으로 부터 오는 데이터(sensory data)로 부터 직접 의사결정을 한다고 간주되어 왔지만 consciousness prior는 agent가 고층위 abstract space에서 예측 및 의사결정을 내릴 수 있게 해준다. 이러한 conciousness prior는 복잡한 의식으로 부터 단순화된 언어를 통하여 표현하는 자연어 발화 과정에도 부합한다. consciousnes는 agent가 현재에 유용한 표현을 만들기 위하여 abstract concept들 중에서 몇몇의 concept에 주목하여 구성된다는 점에서 착안하여 attentive awareness 라고도 볼 수 있다.
Information bottleneck이론이란 데이터 X로부터 관련 정보인 Y로 정보를 압축할 때 Y와의 관련성(accuracy)과 X의 압축성(compression)사이의 최고의 tradeoff를 정보량을 통하여 찾는 기법을 말한다. R_{IB}(\theta) = I(Z, Y; \theta) - \beta I(Z, X; \theta)
Information bottleneck이론이란 데이터 X로부터 관련 정보인 Y로 정보를 압축할 때 Y와의 관련성(accuracy)과 X의 압축성(compression)사이의 최고의 tradeoff를 정보량을 통하여 찾는 기법을 말한다. R_{IB}(\theta) = I(Z, Y; \theta) - \beta I(Z, X; \theta)
Disentanling과정은 기본적으로 x내에서 독립적인 요소를 찾아 각각 다른 z로 나누는 작업이다. 이를 위하여 z의 prior를 independent Gaussian(N(1,0))로 간주하여 근사하거나(Beta-VAE) Batch내의 z의 값을 permutation하여 adversarial training하는 방법으로 독립을 유도하였다(FVAE). 하지만 Beta-VAE는 모든 관측치의 분포를 N(1,0)으로 강제하여 관측치의 차이에 덜 민감하게 만들어 reconstruction의 성능이 떨어진다.
unsupervised하게 이미지를 source domain에서 target domain으로 보내는 것을 image to image translation이라고 한다. 기존의 방법들은 이렇게 다른 도메인으로 mapping하는 방법이 deterministic하다고 간주하여 왔기 때문에 다양한 이미지를 생성할 수 없었다.
기존의 implicit generative model(VAE)들은 hierarchical latent codes를 통하여 데이터의 statistics를 학습할 수 있지만 decoder를 통한 sampling만 가능하고 likelihood function은 tractable하지 않다. 반대로 likelihood function을 학습할 수 있는 autoregressive neural networks(NADE, MADE, PixelCNN)들은 likelihood function을 학습할 수 있는 대신 latent codes를 활용하지 못한다.
기존의 neural autoregressive model(RNN, MADE, PixelRNN/CNN)들은 VAE의 decoder로서 부적합하다고 여겨져왔다. 왜냐하면 이 모델들의 표현력이 너무 강력해서 종종 latent variable들을 무시하고 이미지를 생성했기 때문이다.
MADE나 PixelCNN/RNN과 같은 autoregressive한 neural density estimator들은 좋은 성과를 보여왔다. Normalizing Flow를 사용하면 Planar/radial flow나 inverse Autoregressive Flow와 같은 특정한 변환에 한해서는 빠르게 Density evaluation을 할 수 있어 variational inference에 유용하게 사용되었다. 하지만 새로운 데이터들에 대해서는 효율적으로 계산하기가 어렵기 때문에 density estimation에는 적합하지 않았다.
기존의 DQN은 학습 데이터들 간의 연관관계를 없애기 위하여 데이터들을 Experience Replay에 저장해 두고 랜덤으로 샘플하여 학습하였다. 하지만 모든 경험이 같은 가치를 가지는 것은 아니다. reward가 sparse한 환경의 경우 특정 경험이 더욱 중요한 가치를 가질 수 있다.
기존의 DQN은 특정 지점에서의 action-value function을 근사하기 위하여 모든 state와 action의 값을 모두 평가해야 한다는 단점이 있다. 하지만 대부분의 경우, state의 가치가 중요하고 action으로 인한 가치의 변화가 극명한 경우는 많지 않다. 또한 어차피 행동을 고르기 위해서 action-value function을 근사하기 때문에 모든 state와 action에 대하여 정확한 값을 아는 것이 중요한 것이 아니라 다른 action과 비교한 상대값이 중요하다.
기존의 DQN은 특정 지점에서의 action-value function을 그 state에서 action을 취했을 때 즉각적으로 얻는 reward와 그 다음 상태의 가치를 discount한 값을 더한 것으로 근사한다. 조금 더 근사를 효율적으로 하기 위하여 target 네트워크를 사용하는데 이때 다음 state의 가치를 최선의 action을 한 결과로 판단하기 때문에 낙관하는(overoptimistic) 결과가 나타난다. 이러한 낙관적인 예측은 점진적으로 suboptimal한 policy에 수렴하도록 유도할 수 있다.
기존의 VAE에서는 variational lower bound를 통하여 marginal log-likelihood E_{P_{X}}[log_{P_{G}}(X)를 최대화 하고 Q(z)와 P(z|x)간의 KL Divergence를 최소화하도록 하는 regularization term을 통하여 encoder와 decoder를 학습시켰다.
기존의 대표적인 Generation Model로 VAE와 GAN이 있다. VAE는 목적 분포를 직접 구하는 대신 계산 가능한 다른 분포를 가정하고 이와 목적 분포와의 거리(KL Divergence)를 최소화 함으로써 간접적으로 목적 분포를 구하였다. 하지만 KL Divergence는 두 함수의 support가 같은 영역에서 정의가 되어있어야 한다는 한계가 있다. 또한 GAN은 목적 분포를 직접 구하지 않고도 Discriminator loss를 통하여 표본을 생성하지만 discriminator와 generator간의 학습 비율이 중요하고 섬세하여 학습이 어렵다는 단점이 있다.
기존 machine comprehension 모델들의 attention은 문맥의 조그마한 부분에 주목하여 문맥을 특정 길이의 벡터로 요약을 하고 어탠션을 단방향적으로, temporal하게 적용하였다. 이러한 기존의 attention 방법은 요약하는 과정에서 정보를 손실하기도 하고 순차적으로 이루어지는 attention간에 의존성이 나타나기 때문에 attention의 역할과 model의 역할이 섞이게 된다.
기존 CNN의 문제점은 Max-pooling layer에서 feature의 대략적인 존재여부만 확인하고 정확한 공간정보를 버린다는 것이다. 이 때문에 특징이 어디에 존재하건 존재여부를 확인할 수 있는 invariance한 성질을 가지지만 그 특징이 다른 특징들과 전혀 조화를 이루지 못하더라도 이를 구별하지 못한다. 우리가 원하는 것은 특징의 단순한 존재여부 뿐만 아니라 전체적인 조화까지 고려하는 equivariance의 성질이다.
이미지의 피쳐를 추출할 때, 한 피쳐 값이 이미지에 대하여 우리가 인지할 수 있는 특성을 나타낸다면 이 값을 조정하여 이미지를 의도적으로 생성할 수 있을 것이다. 이렇게 이미지의 feature를 우리가 의도한 방식으로 추출하는 것을 disentangling이라고 한다. 이러한 disentangled factors는 이미지의 특성 및 추상화된 개념을 나타내게 된다.
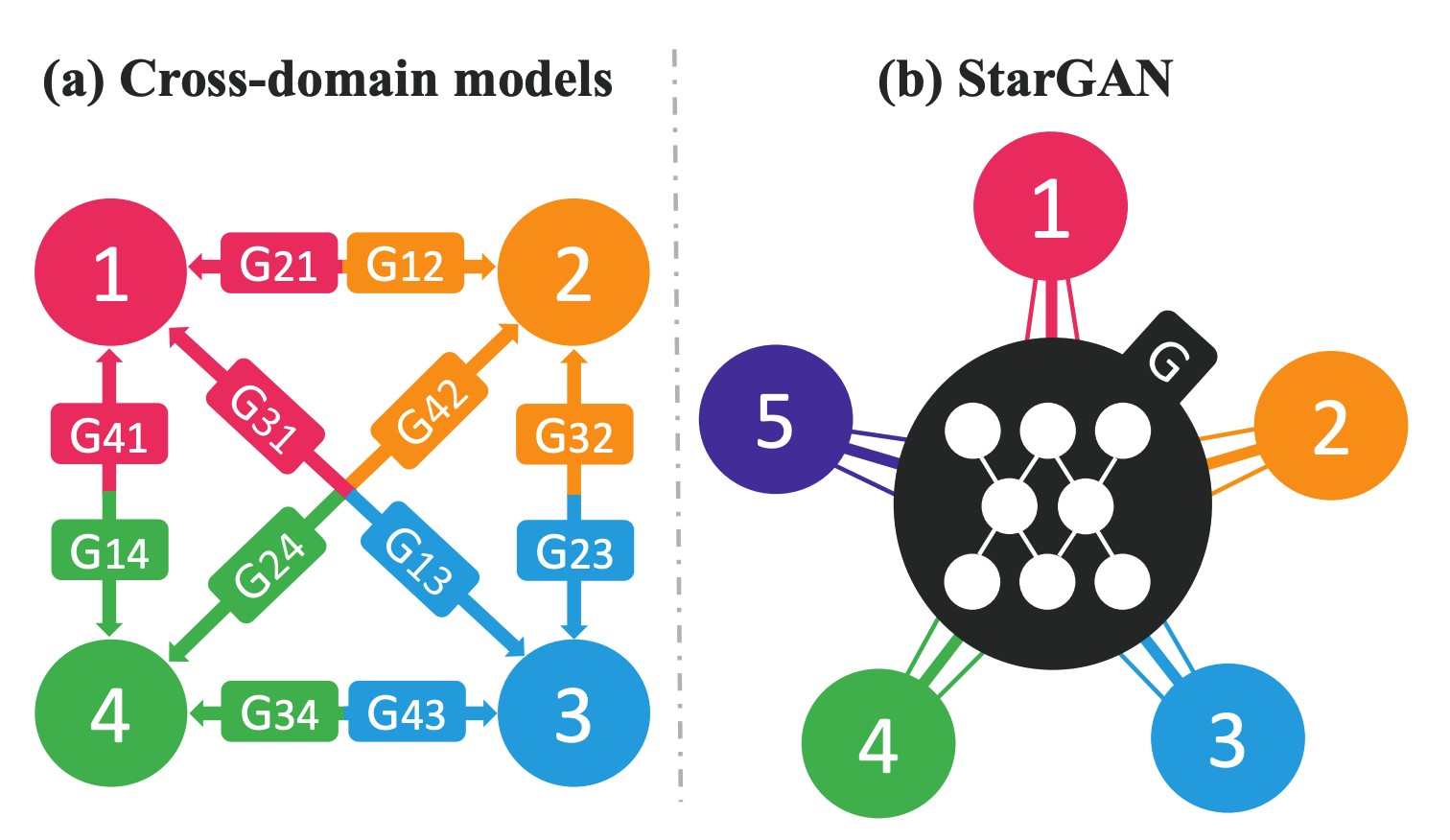
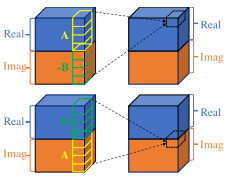
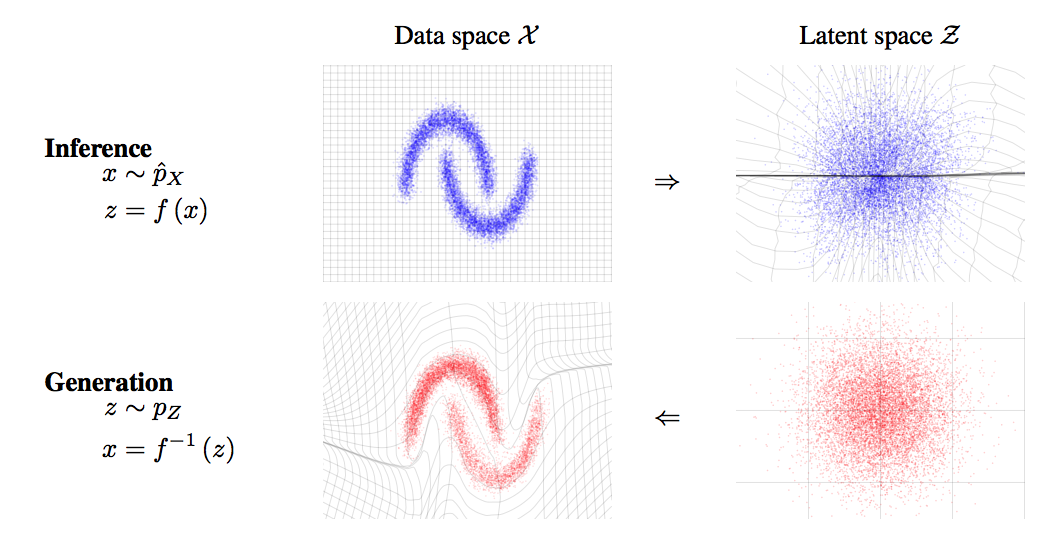 The motivation is almost the same as that of
The motivation is almost the same as that of 
