Large Scale GAN Training for High Fidelity Natural Image Synthesis
WHY?
Generating a high resolution image with GAN is difficult despite of recent advances. This paper suggests BigGAN which adds few tricks on previous model to generate large scale images without progressively growing the network.
WHAT?
BigGAN is made by a series of tricks over baseline model. Self-Attention GAN(SA-GAN) which uses self-attention modules on both generator and discriminator and hindge loss. Class information is provided with class-conditional BatchNorm to generator and with projection to discriminator. Spectral Norm on generator is used. On the top of this baseline model, five major tricks are used.
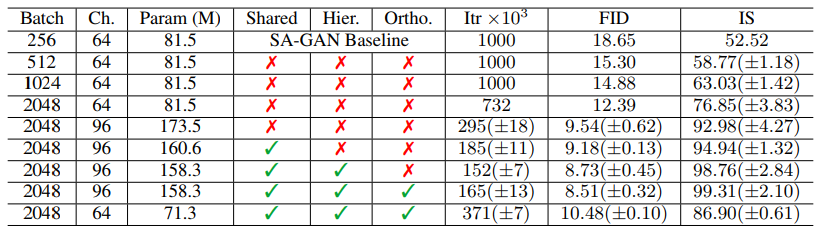
1) Simply increasing the batch size (by a factor of 8: 256 to 2048) greatly improved the performance(46% is IS score). 2) Increasing the capacity by increasing the number of channels(by 50%) in every layer improved the performance(21% is IS score). 3) Shared embedding which is linearly projected to each BatchNorm layer and 4) a variant of hierarchical latent space further improved the performance.
Author also explored new kinds of prior distribution. It turned out that 5) truncated normal distribution can be used to control trade off between variety and fidelity (Truncation Trick). Modified version(below) of Orthogonal Regularization(above) is found to help reducing the saturation artifacts caused by Truncation Trick.
R_{\beta}(W) = \beta\|W^TW - I\|_F^2\\
R_{\beta}(W) = \beta\|W^T W\odot(1-I)\|^2_FSo?
After comprehensive analysis on the training of the model, this paper concluded that stability comes from interaction between discriminator and generator so that reasonable conditioning and relaxing constraints to allow collapse at the later stage are helpful to achieve good results.

BigGAN was able to generate high quality large scale images in quantitative and qualitative measures.

Rejoice in what you learn and spray it!