Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks
WHY?
RNN계열의 sequence model들은 언어모델에 효과적이지만 추론이 느리고 gradient가 사라지거나 long-term dependency를 잡지 못하는 등의 문제점이 있다.
WHAT?
Skip RNN은 State의 update를 skip하면서 계산량을 줄이면서 성능을 유지할 수 있다. 각 State를 skip할 것인지 여부는 state update gate u를 통하여 결정한다. u_t = f_{binarize}(\tilde{u_t})\\ s_t = u_t \cdot S(s_{t-1}, x_t) + (1 - u_t)\cdot s_{t-1}\\ \delta \tilde{u_t} = \sigma(W_p s_t + b_p)\\ \tilde{u_{t+1}} = u_t \cdot \delta \tilde{u_{t+1}} + (1 - u_t) \cdot (\tilde{u_{t+1}} + min(\delta\tilde{u_{t+1}}, 1 - \tilde{u_{t+1}})) 여기서 f_{binarize}는 rounding으로 구현한다. skip이 일정 간격으로 되도록 스킵을 하지 않으면 델타가 축적된다. 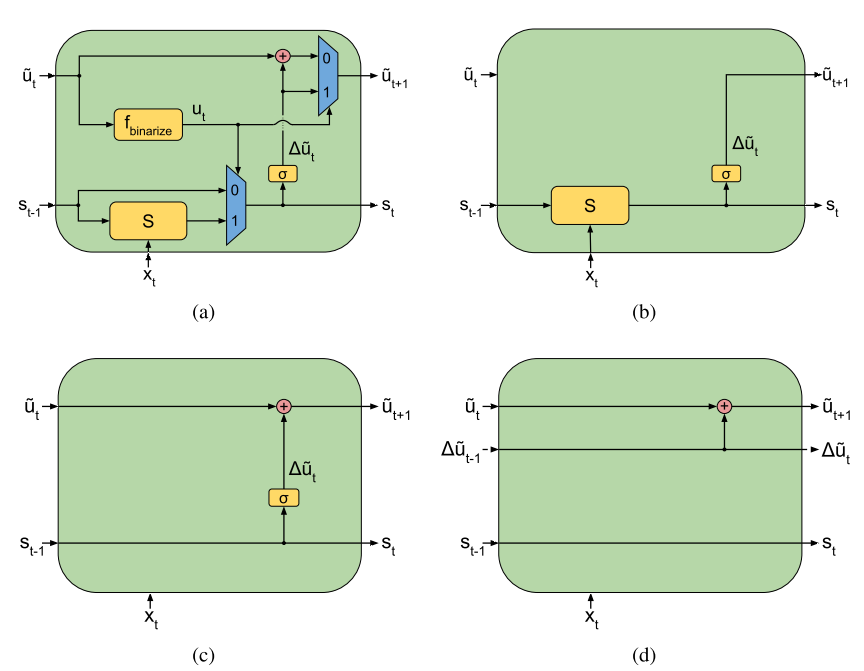 rounding은 gradient가 전파되지 않기 때문에 straight-through estimator를 사용하여 x의 gradient를 1로 근사한다. 또한 task에 따라 skip의 허용 정도가 달라지기 때문에 새로운 term에서 cost per sample term(lambda)를 통하여 조절한다.
rounding은 gradient가 전파되지 않기 때문에 straight-through estimator를 사용하여 x의 gradient를 1로 근사한다. 또한 task에 따라 skip의 허용 정도가 달라지기 때문에 새로운 term에서 cost per sample term(lambda)를 통하여 조절한다.
L_{budget} = \lambda\cdot \Sigma_{t=1}^T u_t
So?
Adding task, MNIST sequential classification, Charades action localization에서 성능을 거의 유지하거나 더 좋은 성과를 보이며 계산량을 획기적으로 줄일 수 있었다.
Critic
task마다 성능 하락 차이가 큰 것 같다.

Rejoice in what you learn and spray it!