Synchronization is an important issue is distributed SGD. Too few synchoronization among nodes causes unstable training while too frequent synchoronization causes high communication cost.
Resilient Distributed Datasets(RDD) is a distributed memory abstraction to perform in-memory computations of large clusters. While many data-processing algorithms are applied to data iteratively, the reuse of intermediate results are rarely exploited. To enable in-memory processing with fault-tolerence, RDD provide an interface based on coarse-grained transformation while logging the transformations in lineage. RDDs is implemented in a system called Spark. Datasets from stable storage go through transfomations such as map, filter and join from RDDs to RDDs. Lineage keep tracks of this transformation to recover from error. Users can choose to persist data for later reuse or partition the data with key values. The programming language of Spark is based on Scala. From driver, driver program connects a cluster of workers. Programmers define RDDs and perform several transformations. Then, actions such as count, collect and save are called to perform all the transformation with actions. They can choose to persist the data for later use.
Hadoop Distributed File System(HDFS) construct file system in cluster level. Huge amount of data are stored in distributed servers and enable users to access with high bandwith. Just like UNIX file system, HDFS keep metadata for data it stores. A dedicated server that stores metadata is called NameNode, and other servers that store application data is called DataNodes. All servers communicate through TCP-based protocol. To enable high bandwith and quick access, HDFS replicate data on multiple DataNodes(usually 3). The metadata that stores the structure of HDFS is called image. To ensure security, the persistent state of the image is recorded as a checkpoint. Also, the changes after a checkpoint is also stored as journal. Image can be restored with the checkpoint and the journal. To improve security, BackupNode that stores state of the image in memory and snapshot that provides roll-out in case of version collision are introduced. NameNode and DataNodes communicate through heartbeat. NameNode provides the nearest DataNode when HDFS read data. Writing is tricky since same data are replicated in several DataNodes. When writing occurs, HDFS pipelines DataNodes to update the data sequentially.
Resource managers successfully support distributed computing framework by allocating jobs to nodes in a cluster. Though this RMs are good at utilizing the resources in a cluster, the process of implementation remains quite bothersome dealing the same tasks repetitively for every RMs and applications. Retainable Evaluator Execution Framework(REEF) is a meta framework between RMs and applications which not only marginalize repetitive trivial works but also enable container and state reuse across different frameworks. REEF contains few key concepts. Driver allocates resources and schedule tasks. Evaluator is a runtime environment that executes tasks. Context is a state management environment in a evaluator that that retain state. Servie is a library in a evaluator that contains frequently used functionalities. REEF provides higher abstraction on top of RM framework letting developers bypassing trivial implementations.
Apache Hadoop is widely used not only for MapReduce jobs but also any kinds of data processing. The first version of Hadoop had 3 critical drawbacks. First, the framework is hard-coded to MapReduce only. Second, the slots for map and reduce functions are static limiting utilization. Third, JobTracker managed all the task processes so that the framework is not scaleable and vulnerable to failure of JobTracker. Apach Hadoop YARN is a new resource manager that separates resource managing and task scheduling. Resource Manager(RM) receives jobs from client and allocate leases of resources(containers). RM comminicates with Node Manager(NM) which manage the resources of a particular node. Accepted jobs are managed by scheduler inside RM, and RM assigns Application Manager(AM) in a node to coordinate application’s execution in the cluster. RM and AM also communicates through heartbeat protocol.
Strengths
More scalable and robust distributed scheduling is possible.
MapReduce is a programming model that parallelize the computation on large data. The computation consists of two functions: a map and a reduce function. First, input data are partitioned into M splits. Map function takes a partition of inputs and produce a set of intermediate key/value pairs. By partitioning the key space(hash(key mod R)), the result can be split into R pieces. Intermediate pairs can be stored in R regions of local disk. Reduce function accesses the local disks of the map workers and groups intermediate pairs with the same key. The master coordinate the location and size of intermediate file regions.
Mesos is a platform that provides cross-framework resource allocation. The greatest challenge for cross-framework resource sharing is that various kinds of frameworks may have their own different scheduling. Mesos overcome this problem by adopting two-level scheduling mechanism called resource offers.
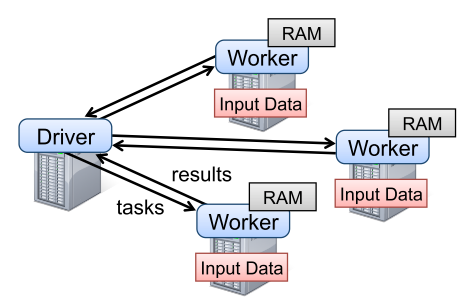 The programming language of Spark is based on Scala. From driver, driver program connects a cluster of workers. Programmers define RDDs and perform several transformations. Then, actions such as count, collect and save are called to perform all the transformation with actions. They can choose to persist the data for later use.
The programming language of Spark is based on Scala. From driver, driver program connects a cluster of workers. Programmers define RDDs and perform several transformations. Then, actions such as count, collect and save are called to perform all the transformation with actions. They can choose to persist the data for later use. 
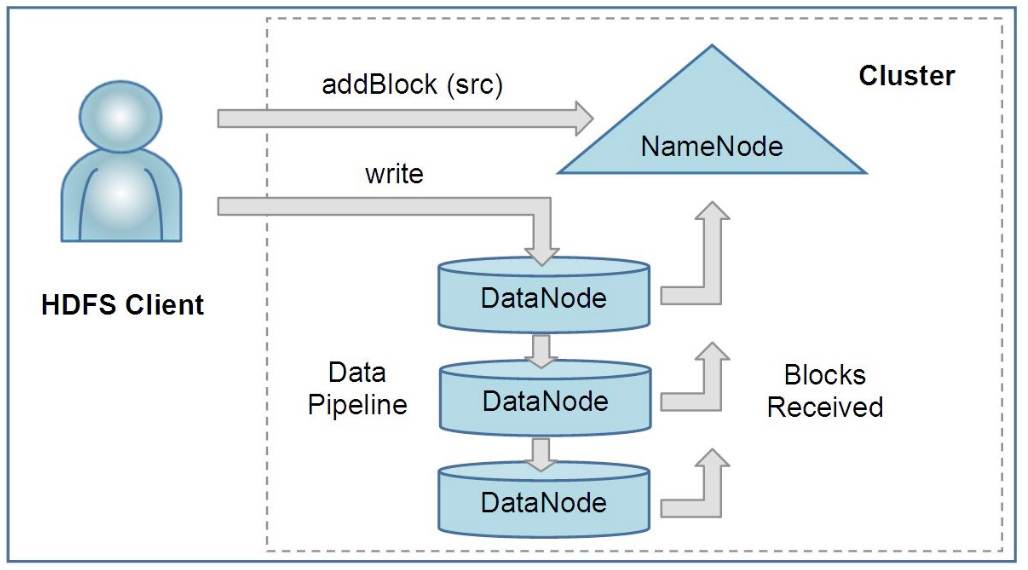 NameNode and DataNodes communicate through heartbeat. NameNode provides the nearest DataNode when HDFS read data. Writing is tricky since same data are replicated in several DataNodes. When writing occurs, HDFS pipelines DataNodes to update the data sequentially.
NameNode and DataNodes communicate through heartbeat. NameNode provides the nearest DataNode when HDFS read data. Writing is tricky since same data are replicated in several DataNodes. When writing occurs, HDFS pipelines DataNodes to update the data sequentially.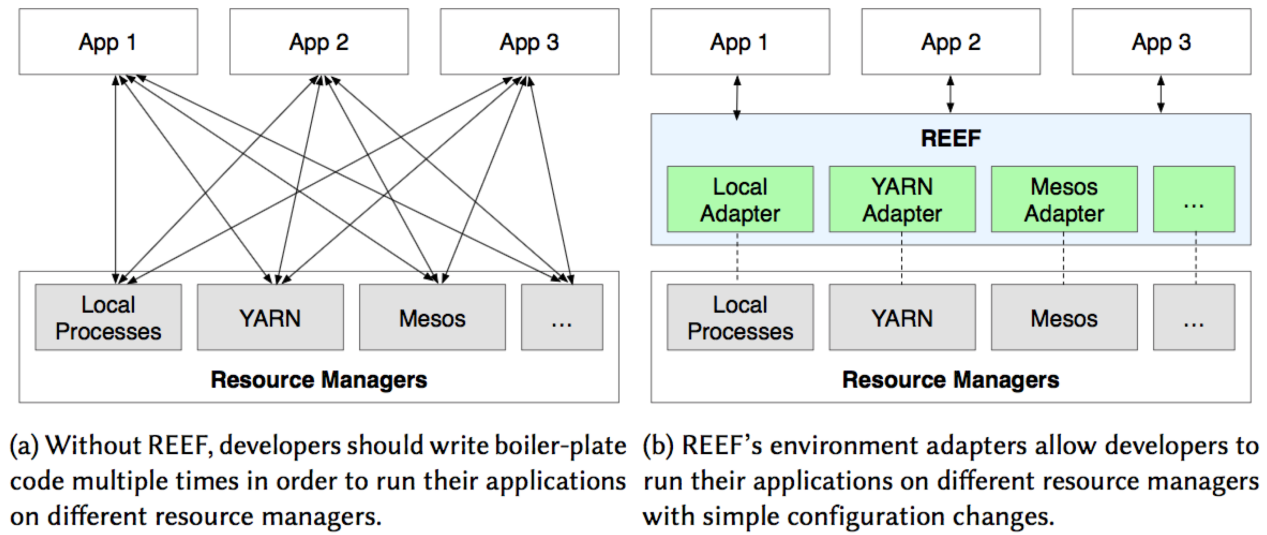 Retainable Evaluator Execution Framework(REEF) is a meta framework between RMs and applications which not only marginalize repetitive trivial works but also enable container and state reuse across different frameworks.
Retainable Evaluator Execution Framework(REEF) is a meta framework between RMs and applications which not only marginalize repetitive trivial works but also enable container and state reuse across different frameworks. 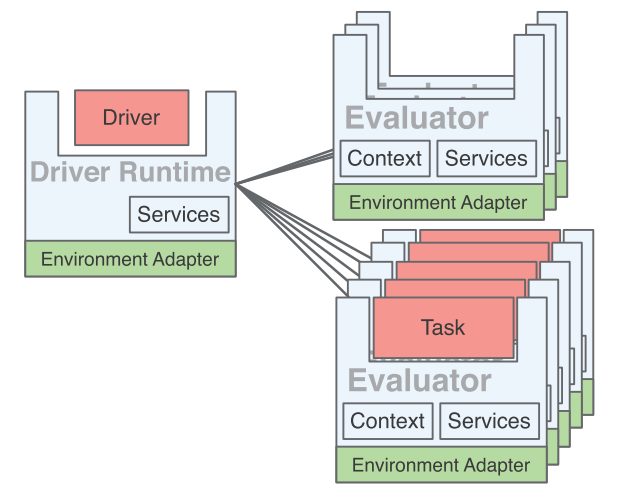 REEF contains few key concepts. Driver allocates resources and schedule tasks. Evaluator is a runtime environment that executes tasks. Context is a state management environment in a evaluator that that retain state. Servie is a library in a evaluator that contains frequently used functionalities.
REEF contains few key concepts. Driver allocates resources and schedule tasks. Evaluator is a runtime environment that executes tasks. Context is a state management environment in a evaluator that that retain state. Servie is a library in a evaluator that contains frequently used functionalities. 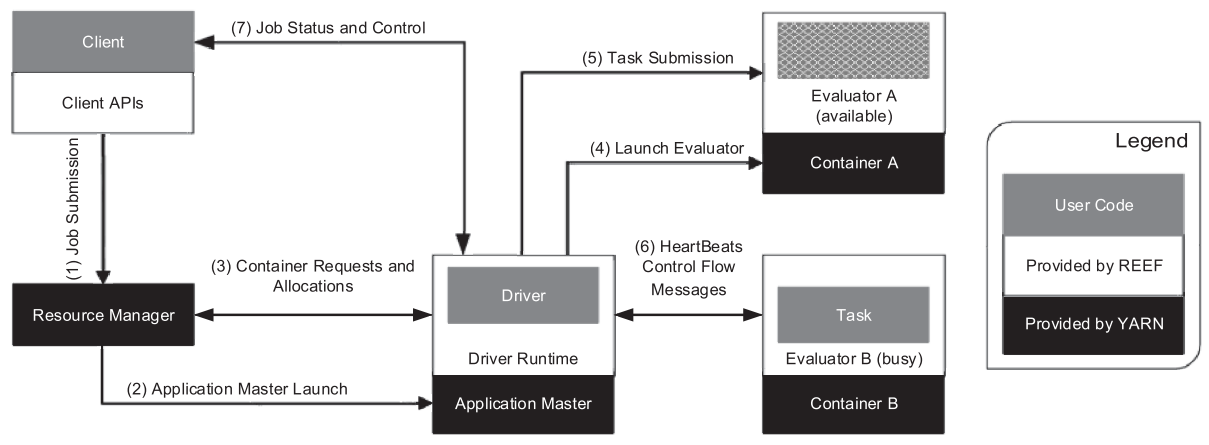 REEF provides higher abstraction on top of RM framework letting developers bypassing trivial implementations.
REEF provides higher abstraction on top of RM framework letting developers bypassing trivial implementations.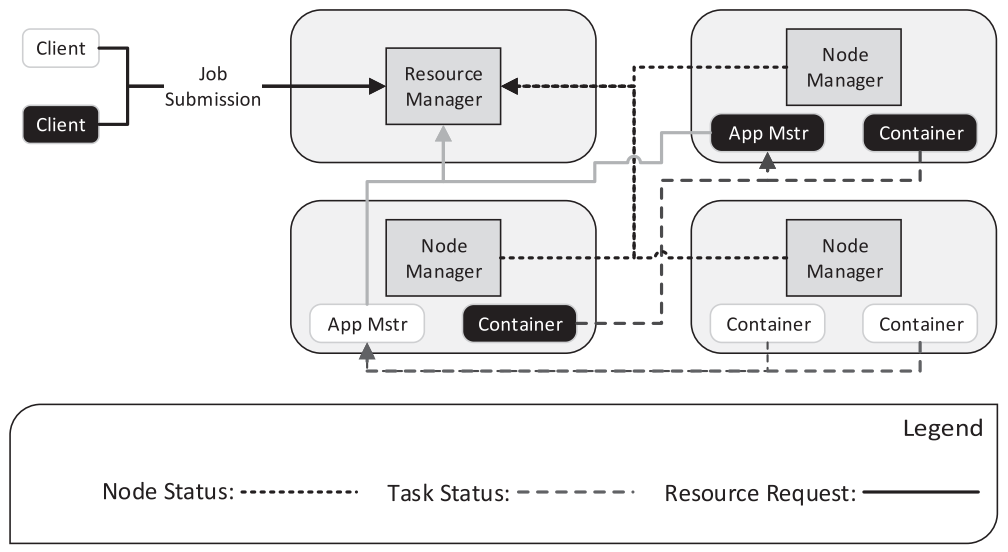 Resource Manager(RM) receives jobs from client and allocate leases of resources(containers). RM comminicates with Node Manager(NM) which manage the resources of a particular node. Accepted jobs are managed by scheduler inside RM, and RM assigns Application Manager(AM) in a node to coordinate application’s execution in the cluster. RM and AM also communicates through heartbeat protocol.
Resource Manager(RM) receives jobs from client and allocate leases of resources(containers). RM comminicates with Node Manager(NM) which manage the resources of a particular node. Accepted jobs are managed by scheduler inside RM, and RM assigns Application Manager(AM) in a node to coordinate application’s execution in the cluster. RM and AM also communicates through heartbeat protocol.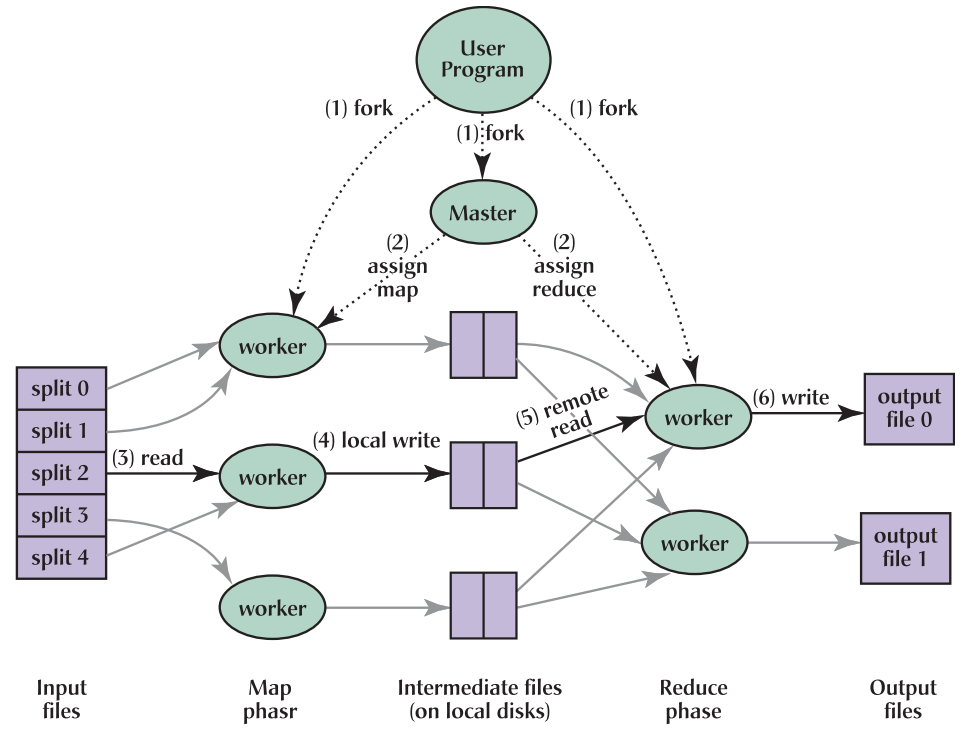 The computation consists of two functions: a map and a reduce function. First, input data are partitioned into M splits. Map function takes a partition of inputs and produce a set of intermediate key/value pairs. By partitioning the key space(hash(key mod R)), the result can be split into R pieces. Intermediate pairs can be stored in R regions of local disk. Reduce function accesses the local disks of the map workers and groups intermediate pairs with the same key. The master coordinate the location and size of intermediate file regions.
The computation consists of two functions: a map and a reduce function. First, input data are partitioned into M splits. Map function takes a partition of inputs and produce a set of intermediate key/value pairs. By partitioning the key space(hash(key mod R)), the result can be split into R pieces. Intermediate pairs can be stored in R regions of local disk. Reduce function accesses the local disks of the map workers and groups intermediate pairs with the same key. The master coordinate the location and size of intermediate file regions. 
