Progressive Growing of GANs for improved Quality, Stability, and Variation
WHY?
Training GAN on high-resolution images is known to be difficult.
WHAT?
This paper suggests new method of training GAN to train progressively from coarse to fine scale.
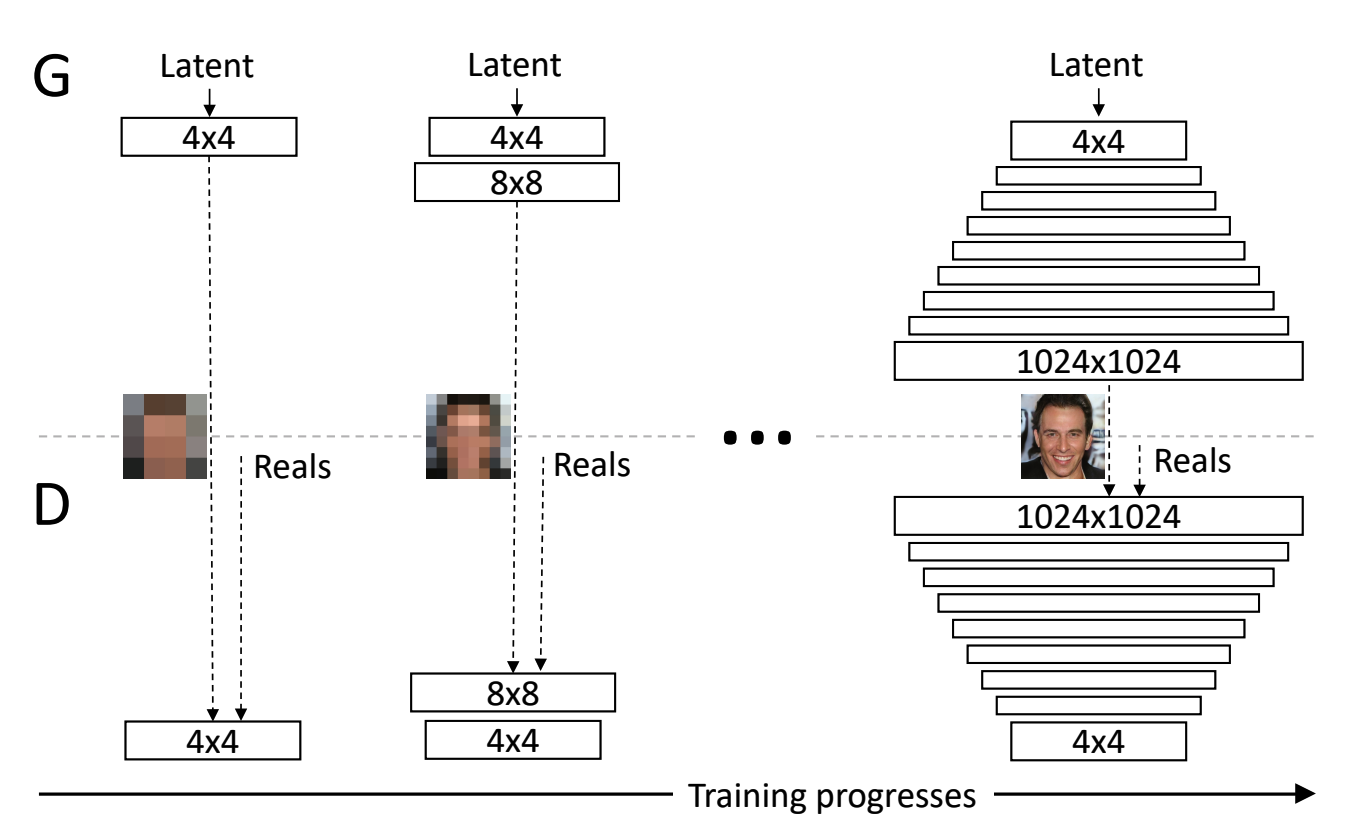
A pair of generator and discriminator are trained with low scale real and fake images at first. As input image size grows, the generator and discriminator add a layer on top of previously learned layers.
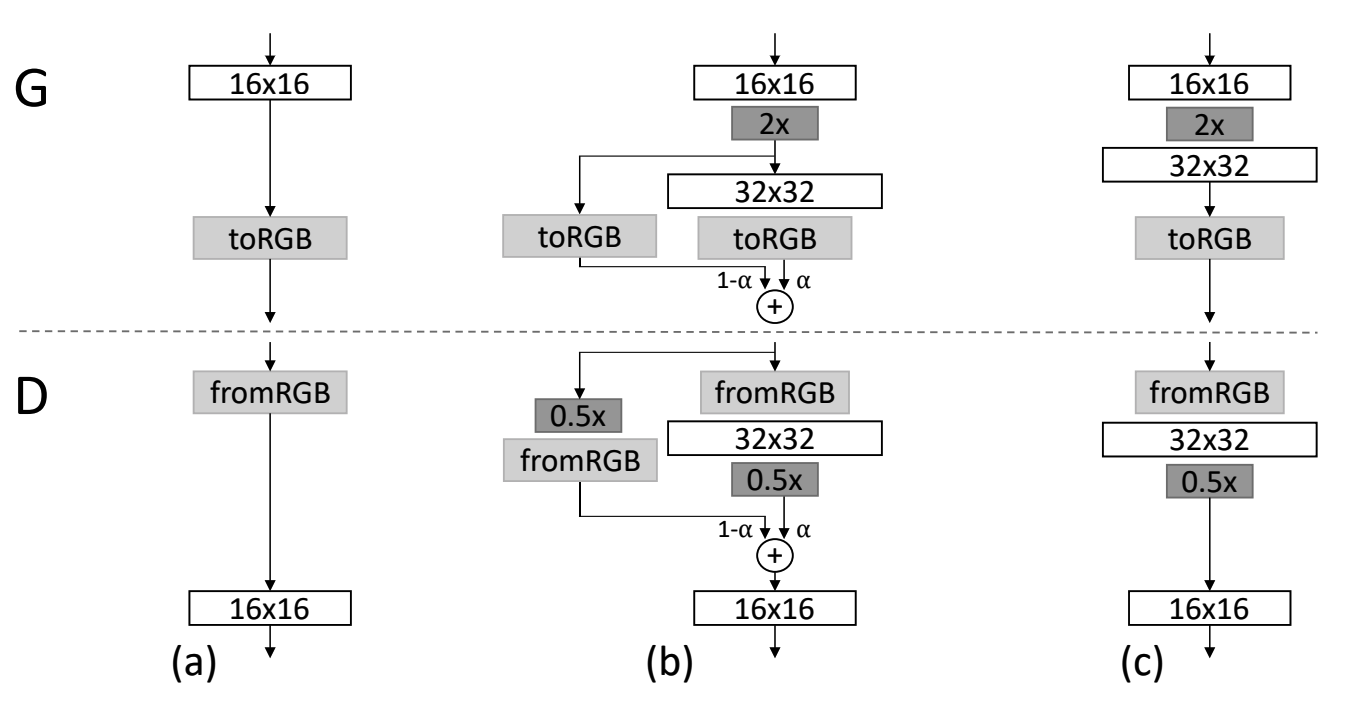
New layer is added smoothly to preserve previously learned layers. Doubling and halving the image is implemented wtih nearest neighbot filtering and average pooling. Weight \alpha increases linearly from 0 to 1.
To increase the variation, the average of standard variation of minibatch is replicated to all spatial location and used as an additional feature map at the end of discriminator.
In order to reduce unhealthy competition between generator and discriminator, this paper suggest two methods. First is to scale the weights at runtime with per-layer normalization constant from He’s initializer(c). Compared to adaptive SGD methods, this method allows to apply equalized learning rate across all weights. Second method is to normalize the feature vector in each pixel to unit length in the generator after each conv layer using “local response normalization”. This prevents the excessive escalation of magnitudes of both network.
So?

This paper suggests using sliced Wasserstein distance(SWD) over MS-SSIM as metric. PGGAN produced better high-resolution images than previous methods in terms of quantitative and qualitative measure.
Critic
Progressive training of GAN is not only intuitive but also super effective method to train networks. Amazing images qualities!

Rejoice in what you learn and spray it!