Disentangling Factors of Variation in Deep Representations Using Adversarial Training
WHY?
한 이미지가 가진 정보에서 label이 가지는 정보와 그 외의 정보로 나뉠 수 있다. 이 두 정보를 분리하여 추출할 때 이에 대한 supervision이 있다면 추출하기가 쉽겠지만 현실 데이터에서는 한계가 있다.
WHAT?
VAE를 사용하여 latent variable을 추출할 때 label의 정보는 spcified component s에 포함되게 하고 그 외의 정보는 unspecified component z에 포함되게 하려고 한다. 이를 위해 Adversarial training을 활용한다. 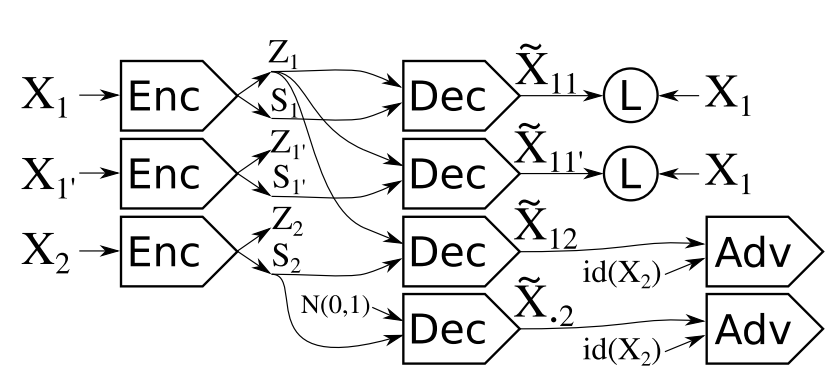 우선 X1의 스타일을 뽑아내기 위하여 같은 레이블의 다른 데이터 하나와 다른 레이블의 데이터 하나가 필요하다. 우선 VAE방법을 사용하여 s1, z1의 정보를 추출하고 이를 통하여 X1을 reconstruct한다. 이때 X1’에서도 s1’, z1’을 추출하되 이번에는 s1’와 z1의 정보를 사용하여 X1으로 reconstruct한다. 이를 통하여 z에 확실히 X1의 스타일 정보가 들어가도록 강제한다. 이때 문제점은 Z1에 레이블의 정보와 스타일의 정보가 모두 들어갈 수 있다는 점이다. 이를 방지하기 위하여 다른 레이블의 데이터를 활용한다. X2에서 z2와 s2를 추출한다. 우선 z2대신 normal noise를 넣고 s2를 활용하여 label2에 대한 adversarial training을 시행한다. 이를 통하여 s2에 최대한의 label정보만 들어가도록 강제한다. 그리고 앞에서 구한 z1과 s2를 활용하여 reconstruct한 데이터를 label2에 대해 adversarial training을 시행한다. 이를 통하여 z1에 레이블에 대한 정보가 들어가는 것을 방지한다.
우선 X1의 스타일을 뽑아내기 위하여 같은 레이블의 다른 데이터 하나와 다른 레이블의 데이터 하나가 필요하다. 우선 VAE방법을 사용하여 s1, z1의 정보를 추출하고 이를 통하여 X1을 reconstruct한다. 이때 X1’에서도 s1’, z1’을 추출하되 이번에는 s1’와 z1의 정보를 사용하여 X1으로 reconstruct한다. 이를 통하여 z에 확실히 X1의 스타일 정보가 들어가도록 강제한다. 이때 문제점은 Z1에 레이블의 정보와 스타일의 정보가 모두 들어갈 수 있다는 점이다. 이를 방지하기 위하여 다른 레이블의 데이터를 활용한다. X2에서 z2와 s2를 추출한다. 우선 z2대신 normal noise를 넣고 s2를 활용하여 label2에 대한 adversarial training을 시행한다. 이를 통하여 s2에 최대한의 label정보만 들어가도록 강제한다. 그리고 앞에서 구한 z1과 s2를 활용하여 reconstruct한 데이터를 label2에 대해 adversarial training을 시행한다. 이를 통하여 z1에 레이블에 대한 정보가 들어가는 것을 방지한다.
So?
supervision이 없는 상황에서도 label의 정보와 스타일의 정보를 잘 분리하였다.

Rejoice in what you learn and spray it!