Learning to See by Moving
in Studies on Deep Learning, Computer Vision
WHY?
Feature learning in Convolution Neural Network requires many hand labeled data. It would be useful if one can use other form of supervision. In nature world, organisms acquire many essential information regarding vision by moving itself(egomotion).
WHAT?
This paper tried to prove that the elementary features learned by egomotion is as useful as the one learned with labeled data by comparing the performance of models that have been pre-trained with each. To learn the features with egomotion, this paper suggests two stram architecture that consists of Base-CNN(BCNN) and Top-CNN(TCNN) and trained to classify the type of transformation. 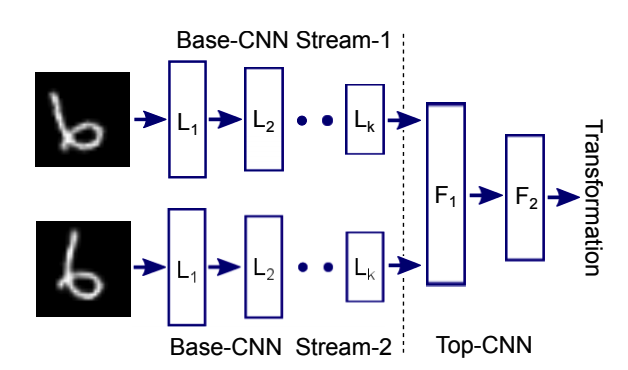 This paper suggest Slow Feature Analysis(SFA) as baseline. Based on the principle that useful features change slowly in time, following contrastive loss make the model learn the features that change slowly.
This paper suggest Slow Feature Analysis(SFA) as baseline. Based on the principle that useful features change slowly in time, following contrastive loss make the model learn the features that change slowly.
L(x_{t_1}, x_{t_2}, W) = \begin{array}{lr}D(x_{t_1}, x_{t_2}) & if |t_1 - t_2| \leq T \\ 1 - max(0, m - D(x_{t_1}, x_{t_2})) & if |t_1 - t_2| > T \end{array}
So?
This paper proved its concept by validating elementary features learned with MNIST with translation. And then, the model learned elementary features using the dataset of KITTI and SF.  The pretrained model showed comparable result to that of AlexNet from scratch, or features learned with SFA in Scene Recognition, Object Recognition, Intra-class keypoint matching and Visual Odometry. Learnt feature may differ by the datasets used for training.
The pretrained model showed comparable result to that of AlexNet from scratch, or features learned with SFA in Scene Recognition, Object Recognition, Intra-class keypoint matching and Visual Odometry. Learnt feature may differ by the datasets used for training.
Critic
Very intuitive idea. I think not only elementary features, but also mid level features can be learned from moving(like entity). Something worthy to think about.

Rejoice in what you learn and spray it!