Attention is all you need
WHY?
기존의 sequence transduction모델들은 복잡한 RNN이나 CNN을 기반으로 하였고 attention mechanism을 활용하였다.
WHAT?
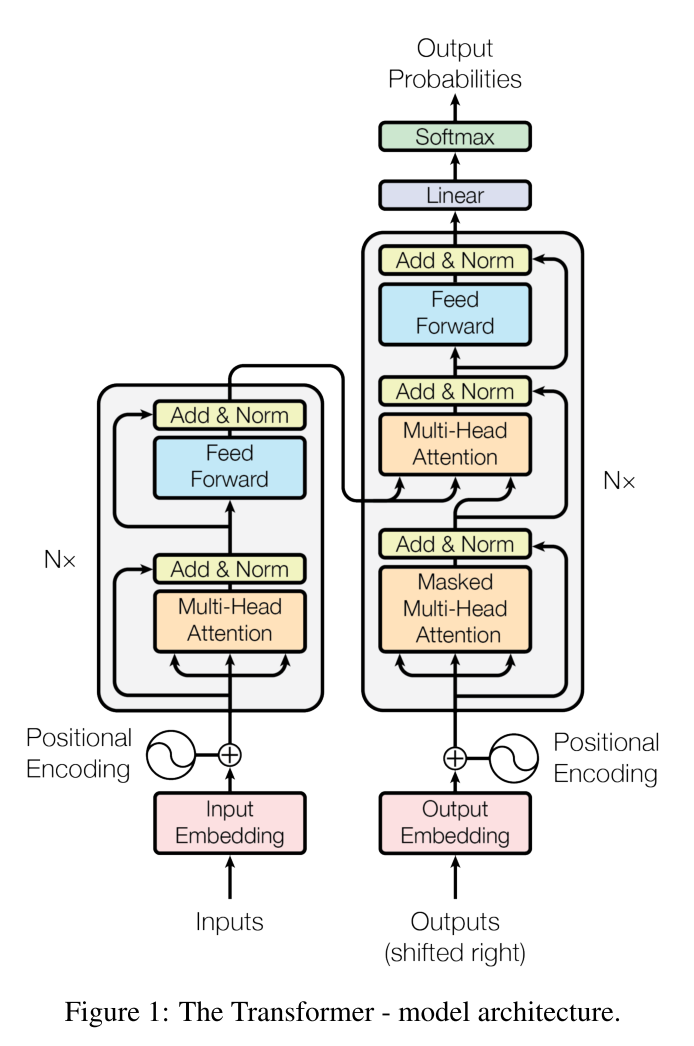
저자는 RNN이나 CNN구조를 제외하고 attention만을 사용하여 좋은 성능을 내는 모델을 제안하였다. 모델 구조는 다음과 같다.
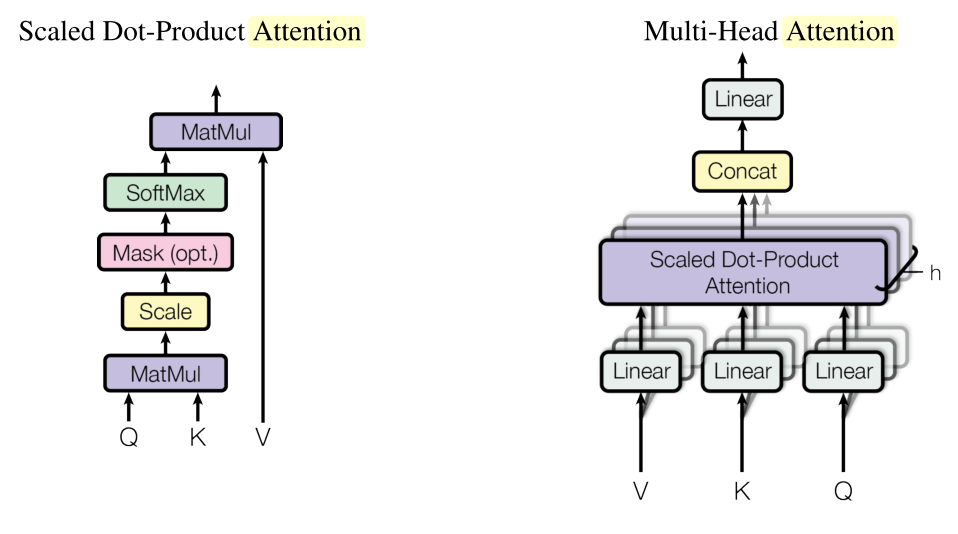
여기서 Multi-head self-attention은 한 문장 내에서 단어들과 다른 단어들 간의 Scaled Dot-Product Attention으로 구성된다. Scaled Dot-Product Attention은 기존의 attention과는 달리 한 input vector를 key와 value라는 두가지 representation으로 분리하고 key와 query(self attention이기 때문에 문장 내의 다른 단어들)의 dot product를 통하여 attention weight를 정한다. 그리고 이 weight에 따라 value를 가중합하여 context가 반영된 representation을 도출한다. 이 결과 h개를 concate하여 fc한 결과가 output이 된다. self attention이므로 이 과정은 parallize가 가능하다.
인풋에 positional encoding을 하고 이를 encoder, decoder의 Multi-head attention에 모델과 같이 stack하여 결과를 도출할 수 있다.
So?
기존의 seq-seq모델보다 훨씬 빠르면서도 우수한 성과를 내었다.

Rejoice in what you learn and spray it!