Learning Hierarchical Features from Generative models
WHY?
NN모델들은 이미지를 인식/분류할 때 계층적 특징들을 학습한다. 하지만 Generative model들은 계층적으로 생성하지 않는다. Stacked Hierarchy를 가지고 있는 HVAE(Hierarchical VAE)같은 경우는 계층적인 구조를 가지고 있지만 각 층이 계층적인 특징을 학습하지 못한다. 마지막 층(Bottom layer)에 정보가 충분하여 마지막 층만 사용하여 이미지를 reconstruct할 수 있다. 하지만 마지막 층만 사용한다면 unimodal하기 때문에 multimodal한 구조를 잡지 못하고 특징들은 disentangle되지 못한다.
WHAT?
이 논문에서 제안하는 모델과 유사한 것은 LVAE이다. LVAE는 모든 층에 정보를 분산하는 것에 성공했지만 이 정보들이 계층적인 정보를 담고 있지는 않았다는 한계가 있다. . 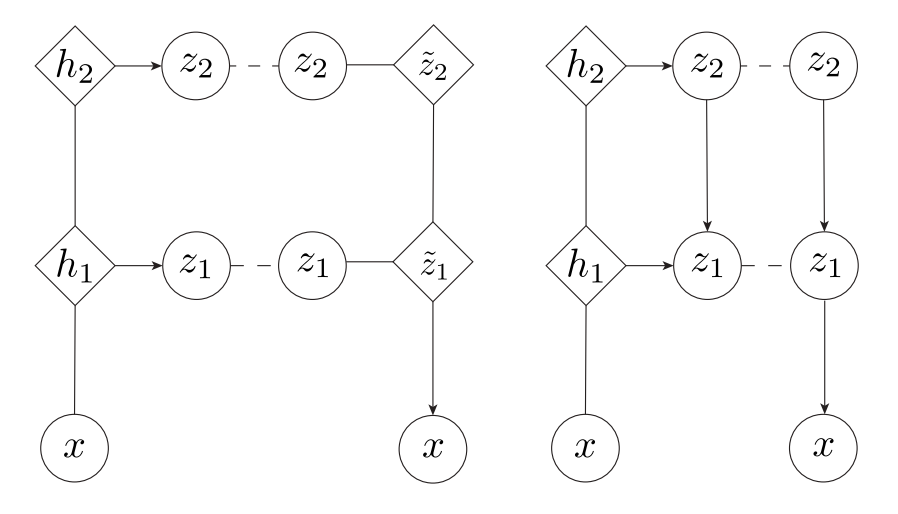 그림의 오른쪽이 LVAE이고 왼쪽이 논문에서 제안한 VLAE(Variational Laddr Autoencoder)이다. Generative network는
그림의 오른쪽이 LVAE이고 왼쪽이 논문에서 제안한 VLAE(Variational Laddr Autoencoder)이다. Generative network는 \tilde{z}_L=f_L(z_L)\\ \tilde{z}_l = f_l(\tilde{z}_{l+1}, z_l) l = 1, ..., L-1\\ x\sim r(x; f_0(\tilde{z}_1))\\ f_l(\tilde{z}_{l+1}, z_l) = u_l([\tilde{z}_{l+1}; v_l(z_l)]) 여기서 u와 v는 nn이고 r은 fixed variance Gaussian을 사용하였다. Inference network는 h_l = g_l(h_{l-1})\\ z_l /sim N(u_l(h_l), \sigma_l(h_l)) 여기서 주의할 것은 z들 사이의 conditional probability가 정의되지 않았다는 점이다. 그렇기 때문에 본질적으로는 한 층의 VAE와 같지만 inference network의 구조를 통하여 간접적으로 계층적인 특징을 학습한다는 점에서 flat hierarchy라고 한다.
So?
 MNIST, SVHN, CelebA에서 각 층들이 계층적으로 독립적인 특징을 학습하게 하는데 성공하였다. 특히 inference network처럼 낮은 층에는 세부적인 특징이 높은 층에는 전체적인 구조의 특징이 학습되었다(색 - 스타일 - 숫자 - 구조).
MNIST, SVHN, CelebA에서 각 층들이 계층적으로 독립적인 특징을 학습하게 하는데 성공하였다. 특히 inference network처럼 낮은 층에는 세부적인 특징이 높은 층에는 전체적인 구조의 특징이 학습되었다(색 - 스타일 - 숫자 - 구조).
Critic
각 층이 왜 독립적인 특징들이 학습되는지 신기하다. 계층적인 특징을 학습하는 만큼 reconstruction도 잘 되는지 궁금하다.

Rejoice in what you learn and spray it!