Learning Disentangled Representations with Semi-Supervised Deep Generative Models
WHY?
VAE구조를 활용하여 semi-superviesd training을 할 때 label정보를 활용하여 label에 관한 정보와 그 외의 정보를 disentangle하고자 한다.
WHAT?
semi-supervised training은 label이 있는 데이터와 label이 없는 데이터에 따라 목적식이 두가지로 구분된다. label이 없는 데이터의 식은 기존의 unsupervised와 같으므로 생략하고 label이 있는 데이터의 목적식을 다음과 같이 변형할 수 있다. 그리고 weight에 따라 importance sampling을 하여 값을 추정할 수 있고 이를 대입하면 마지막 식이 도출된다. \mathcal{L}(\theta, \phi; \mathcal{D}, \mathcal{D}^{sup}) = \Sigma_{n=1}^{N} \mathcal{L}(\theta, \phi; \mathbb{x}^n) + \gamma \Sigma_{m=1}^{M} \mathcal{L}^{sup}(\theta, \phi; \mathbf{x}^m, \mathbf{y}^m)\\ \mathcal{L}^{sup}(\theta, \phi; \mathbf{x}^m, \mathbf{y}^m) = \mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x}^m, \mathbf{y}^m)}[log\frac{p_{\theta}(\mathbf{x}^m, \mathbf{y}^m, \mathbf{z}^m)}{q_{\phi}(\mathbf{z}|\mathbf{x}^m, \mathbf{y}^m)}] + \alpha log q_{\phi}(\mathbf{y}^m|\mathbf{x}^m)\\ =\mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x}^m, \mathbf{y}^m)}[log\frac{p_{\theta}(\mathbf{x}^m, \mathbf{y}^m, \mathbf{z}^m)}{q_{\phi}(\mathbf{y}^m), \mathbf{z}|\mathbf{x}^m}] + (1+\alpha) log q_{\phi}(\mathbf{y}^m|\mathbf{x}^m)\\ \mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x}^m, \mathbf{y}^m)}[log\frac{p_{\theta}(\mathbf{x}^m, \mathbf{y}^m, \mathbf{z}^m)}{q_{\phi}(\mathbf{y}^m), \mathbf{z}|\mathbf{x}^m}] \simeq \frac{1}{S}\Sigma^S_{s=1} \frac{w^{m, s}}{Z^m}log\frac{p_{\theta}(\mathbf{x}^m, \mathbf{y}^m, \mathbf{z}^{m,s})}{q_{\phi}(\mathbf{y}^m), \mathbf{z}^{m, s}|\mathbf{x}^m}\\ w^{m, s} := \frac{q_{\phi}(\mathbf{y}^m), \mathbf{z}^{m, s}|\mathbf{x}^m}{q_{\phi}(\mathbf{z}^{m, s}|\mathbf{x}^m}\\ \mathcal{L}^{sup}(\theta, \phi; \mathbf{x}^m, \mathbf{y}^m) := \frac{1}{S}\Sigma^S_{s=1} \frac{w^{m, s}}{Z^m}log\frac{p_{\theta}(\mathbf{x}^m, \mathbf{y}^m, \mathbf{z}^{m,s})}{q_{\phi}(\mathbf{y}^m), \mathbf{z}^{m, s}|\mathbf{x}^m} + (1+\alpha) log q_{\phi}(\mathbf{y}^m|\mathbf{x}^m) 주의할 부분은 이 목적식은 어떠한 conditional dependency구조를 가지고 있던 간에 관계없이 사용할 수 있다는 점이다. 이를 확률그래프로 나타내면 다음과 같이 나타낼 수 있다. 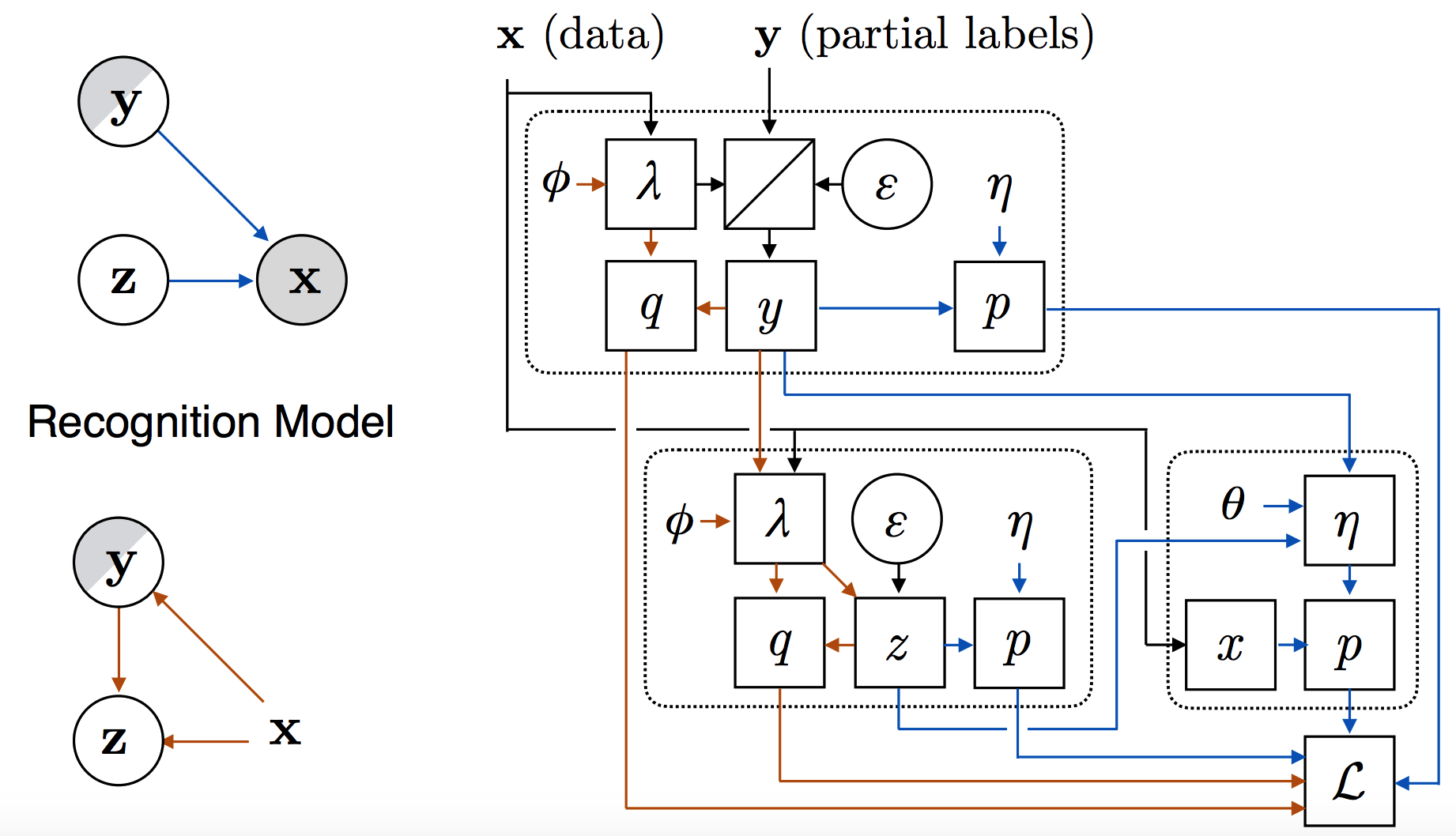 위 그림에는 fully supervised variable x와 unobserbed variable z, partially observed variable y를 중심으로 각각의 분포
위 그림에는 fully supervised variable x와 unobserbed variable z, partially observed variable y를 중심으로 각각의 분포 \lambda, q, p, 그리고 그의 파라미터 \phi, \theta, \eta로 구성되어 있고 reparamerization trick이 사용되었다.
So?
MNIST, SVHN, Intrinsic face, Multi-MNIST에 대하여 좋은 semi-supervise 성능을 거두었다.
Critic
어떤 dependency도 모델링할 수 있는 generalized graph model을 제안했다는 점이 좋았다. 사실 importance sampling부분과 graphical model쪽은 잘 이해를 못했는데 이를 어떻게 구현해야할지 잘 감이 안온다. graphical model쪽은 더 공부해보고 싶다. 이 논문은 다시 읽어보도록 하자.

Rejoice in what you learn and spray it!