Multimodal Unsupervised Image-to-Image Translation
WHY?
unsupervised하게 이미지를 source domain에서 target domain으로 보내는 것을 image to image translation이라고 한다. 기존의 방법들은 이렇게 다른 도메인으로 mapping하는 방법이 deterministic하다고 간주하여 왔기 때문에 다양한 이미지를 생성할 수 없었다.
WHAT?
MUNIT은 이미지 representation을 content code와 style code로 분리한다. content code는 동물의 자세와 같이 여러 도메인에서 공통적으로 나타나는 추상적인 특징을 의미하고 style code는 동물의 종류와 같이 특정 도메인만의 특징을 나타낸다. 그리하여 다른 도메인 사이에서도 공유할 수 있는 공통의 content space가 있고 각 도메인은 자기만의 style space를 가진다고 가정한다. 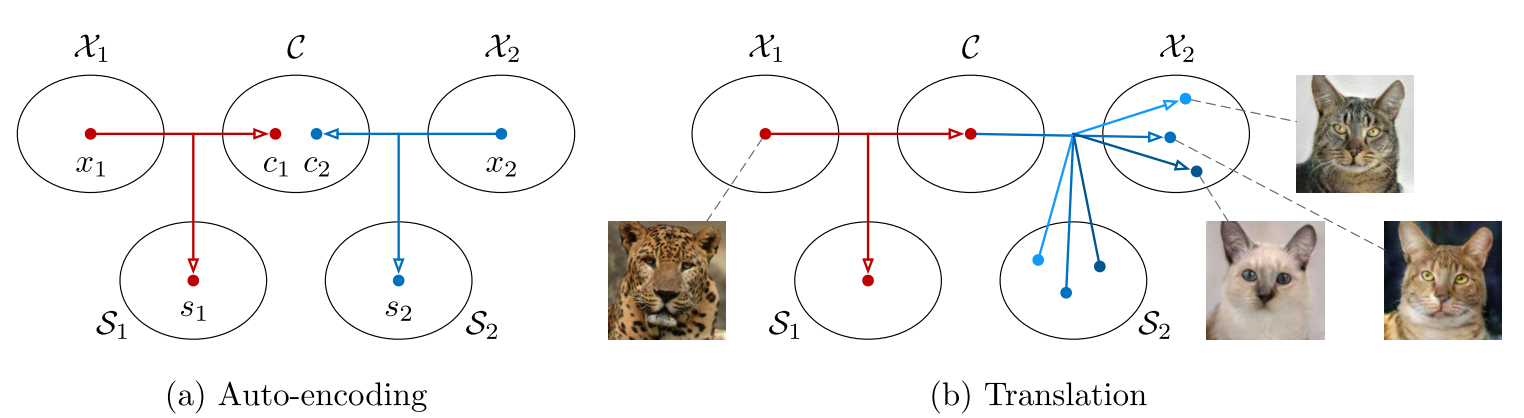 MUNIT의 모델은 각 도메인에서의 encoder와 decoder로 이루어진다. 각 encoder는 content encoder와 style encoder로 구성된다.
MUNIT의 모델은 각 도메인에서의 encoder와 decoder로 이루어진다. 각 encoder는 content encoder와 style encoder로 구성된다. 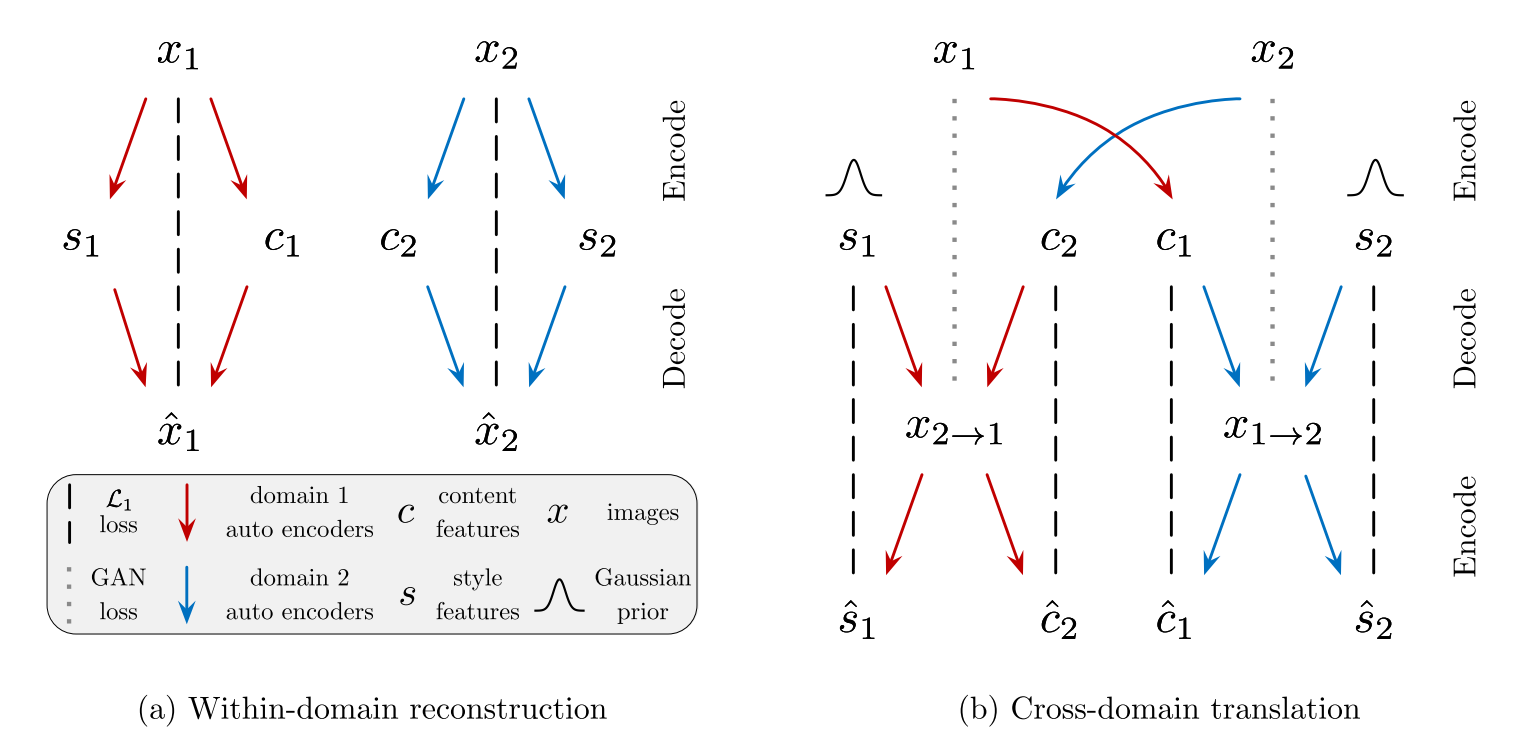 이 모델에서는 Bidirectional reconstruction loss를 가진다. Image reconstruction term은 각 도메인의 이미지에 대하여 content code와 style code를 추출한 후 다시 이미지를 복원하도록 encoder와 decoder를 학습한다. Cross-domain translation을 위하여 각 도메인의 content code를 추출한 후 단순한 분포를 가정하고 있는 상대의 style code와 결합한다. 이렇게 도출된 결과에 다시 상대 도메인의 인코더를 사용하였을 때 content code와 style code가 복원되도록 latent reconstruction loss를 최소화한다. 동시에 중간에 생성했던 결과가 상대 도메인의 데이터들과 비슷해 지도록 adversarial loss를 최소화한다. Loss term들을 요약하면 다음과 같다.
이 모델에서는 Bidirectional reconstruction loss를 가진다. Image reconstruction term은 각 도메인의 이미지에 대하여 content code와 style code를 추출한 후 다시 이미지를 복원하도록 encoder와 decoder를 학습한다. Cross-domain translation을 위하여 각 도메인의 content code를 추출한 후 단순한 분포를 가정하고 있는 상대의 style code와 결합한다. 이렇게 도출된 결과에 다시 상대 도메인의 인코더를 사용하였을 때 content code와 style code가 복원되도록 latent reconstruction loss를 최소화한다. 동시에 중간에 생성했던 결과가 상대 도메인의 데이터들과 비슷해 지도록 adversarial loss를 최소화한다. Loss term들을 요약하면 다음과 같다. min_{E_1, E_2, G_1, G_2} max_{D_1, D_2} \mathfrak{L}(E_1, E_2, G_1, G_2, D_1, D_2)\\ = \mathfrak{L}^{x_1}_{GAN} + \mathfrak{L}^{x_2}_{GAN} + \lambda_x (\mathfrak{L}^{x_1}_{RECON} + \mathfrak{L}^{x_2}_{RECON}) + \lambda_c (\mathfrak{L}^{c_1}_{RECON} + \mathfrak{L}^{c_2}_{RECON}) \lambda_s (\mathfrak{L}^{s_1}_{RECON} + \mathfrak{L}^{s_2}_{RECON}) 구체적인 구조는 다음과 같다. 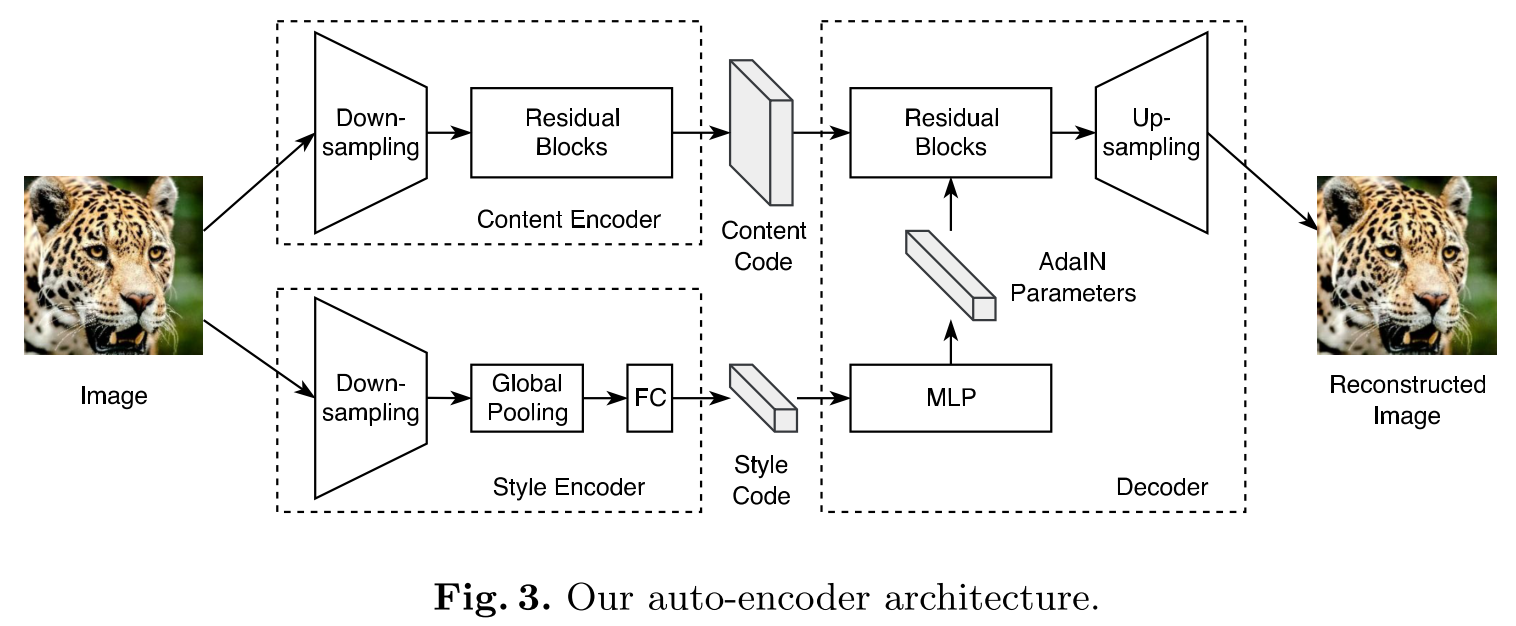
So?
Unsupervised하게 높은 성능의 image translation을 하면서도 다양한 이미지를 추출할 수 있게 되었다. content space를 통하여 다양한 도메인들 사이에서 추상화를 이룬 점이 인상깊었다.

Rejoice in what you learn and spray it!