Deep Compositional Question Answering with Neural Module Networks
in Studies on Deep Learning, Computer Vision
WHY?
Visual question answering task is compositional in nature.
WHAT?
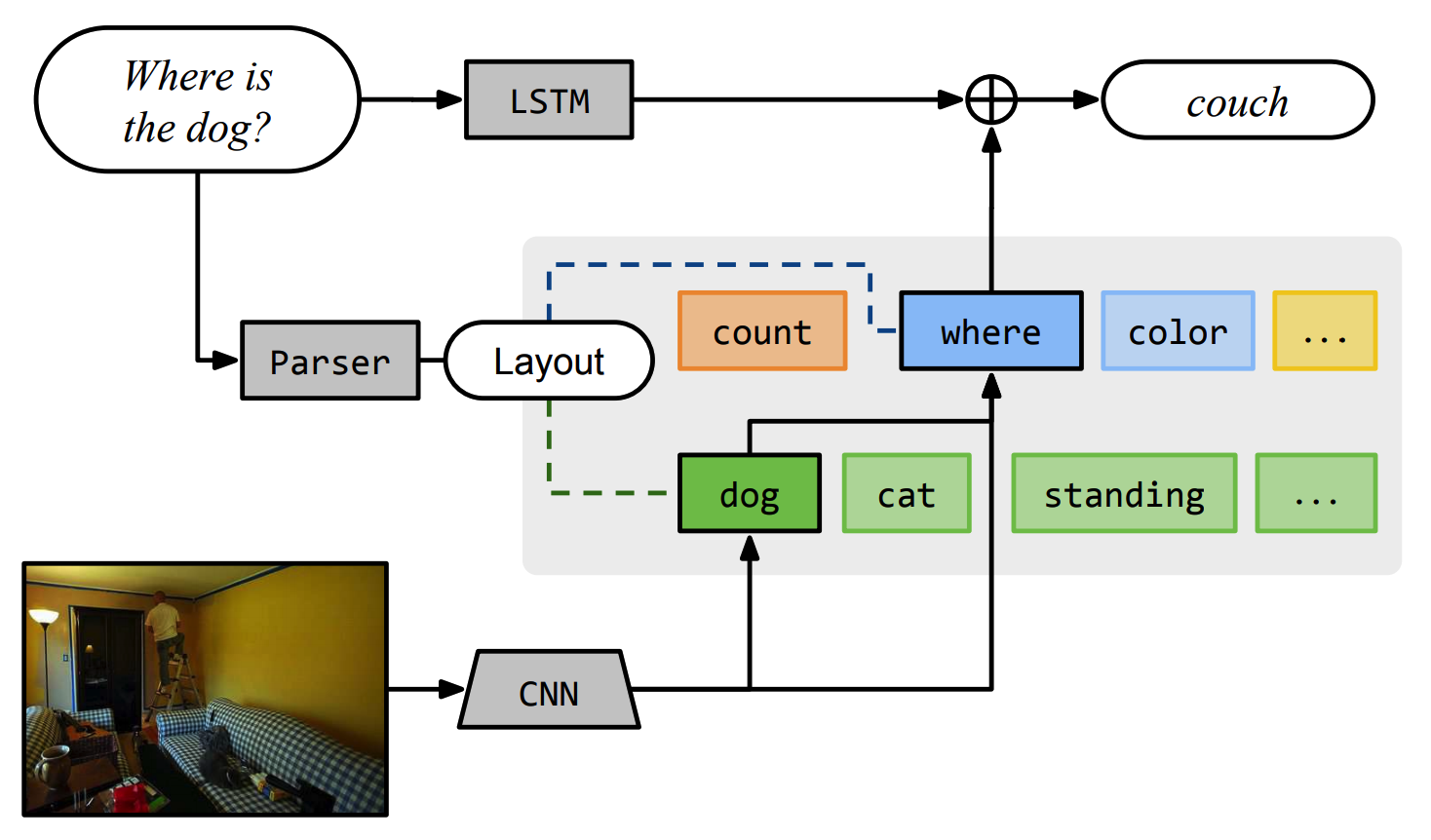
This paper tries to solve VQA by composing modeules to construct a network architecture based on a given question. Primitive modules that can be composed into any configuration of questions are defined: attention, re-attention, combination, classification, and measurement. The key component of the modules is attention mechanism that allow model to focus on the parts of the given image. A question is parsed to form an universal dependency representation which can be map into a network layout. Embedded question is combined to the end of network to capture subtle differences. The composed model is trained end-to-end.
So?

This model achieved the best performance on VQA and SHAPES datasets.

Rejoice in what you learn and spray it!