Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
WHY?
This paper describe several tips and tricks for VQA challenge with the first place model in 2017 VQA challenge. Also, this paper conducts comprehensive experiment for ablation of each trick.
WHAT?

The architecture of this model is rather simple. As question embedding, GRU(512) with pretrained GloVe word vector(300) is used as initialization. Maximum length of thq question is timmed to 14. As image feature, this paper tries 2 methods: the output of pretrained Resnet resized to 7 x 7 with average pooling, and bottom-up attention with Faster R-CNN (K=60). This paper used only one glimpse of image attention instead of many glimpse of attention. Multi-modal fusion is implemented with Hadamard product.
This paper elaborates 6 major tricks for VQA challenge. First, instead of single-label classification, this paper allowed multi-labels using sigmoid output. Then, the objective function of this paper becomes binary cross entropy loss. Second, instead of one hard score of 1, soft score of accuracy(s = min(m/3, 1)) is used using the information from multiple human annotators. Third, gated tanh activation is used for non-linear layers instead of general ReLU. This paper showed that image features from bottom-up attention is better than grid-like feature map. Also, initializing classifier with pretrained word-vecter is showen to be useful. Lastly, using large mini-batches and smart shuffling further improved the performance. The ablation is showen as below.
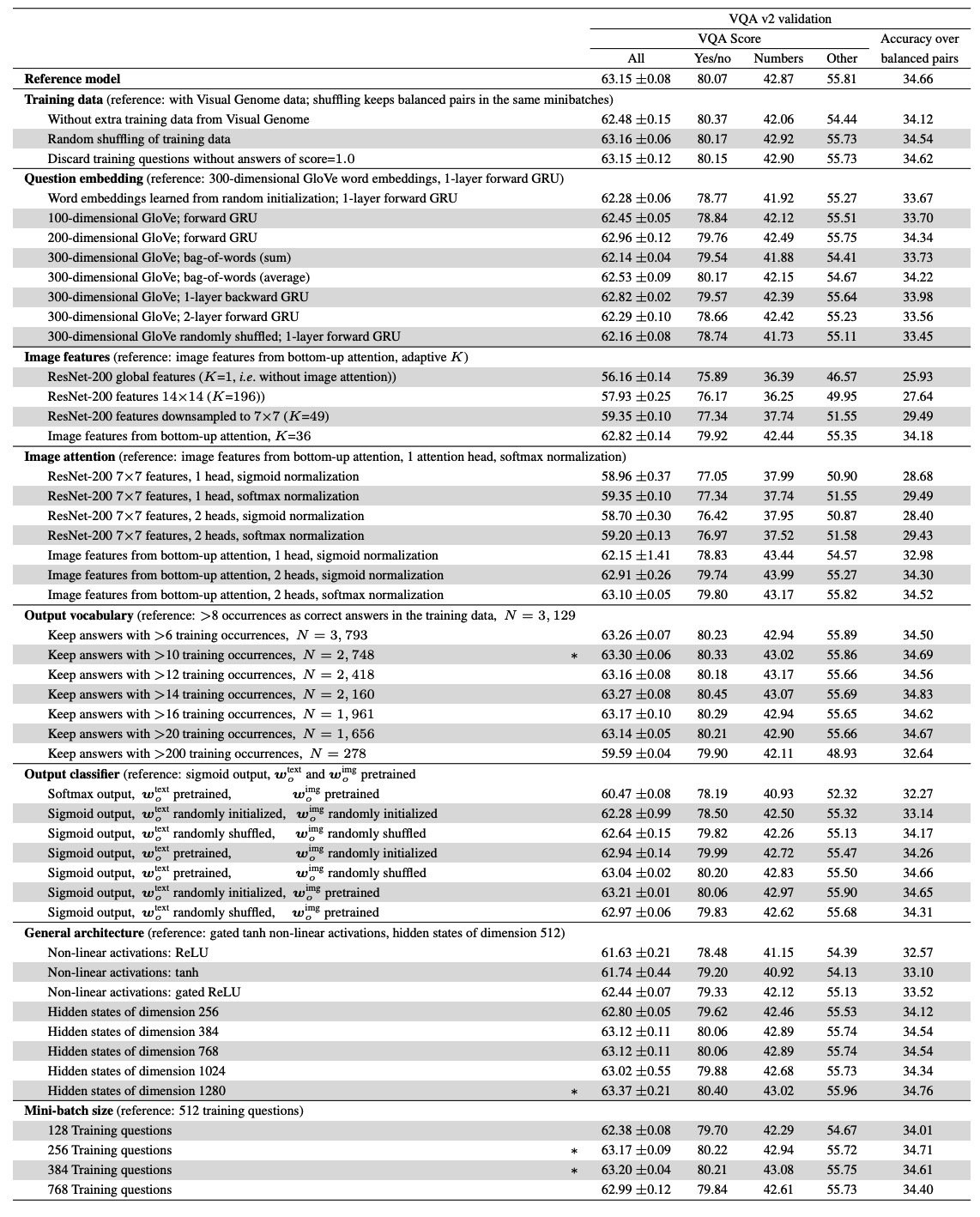
So?
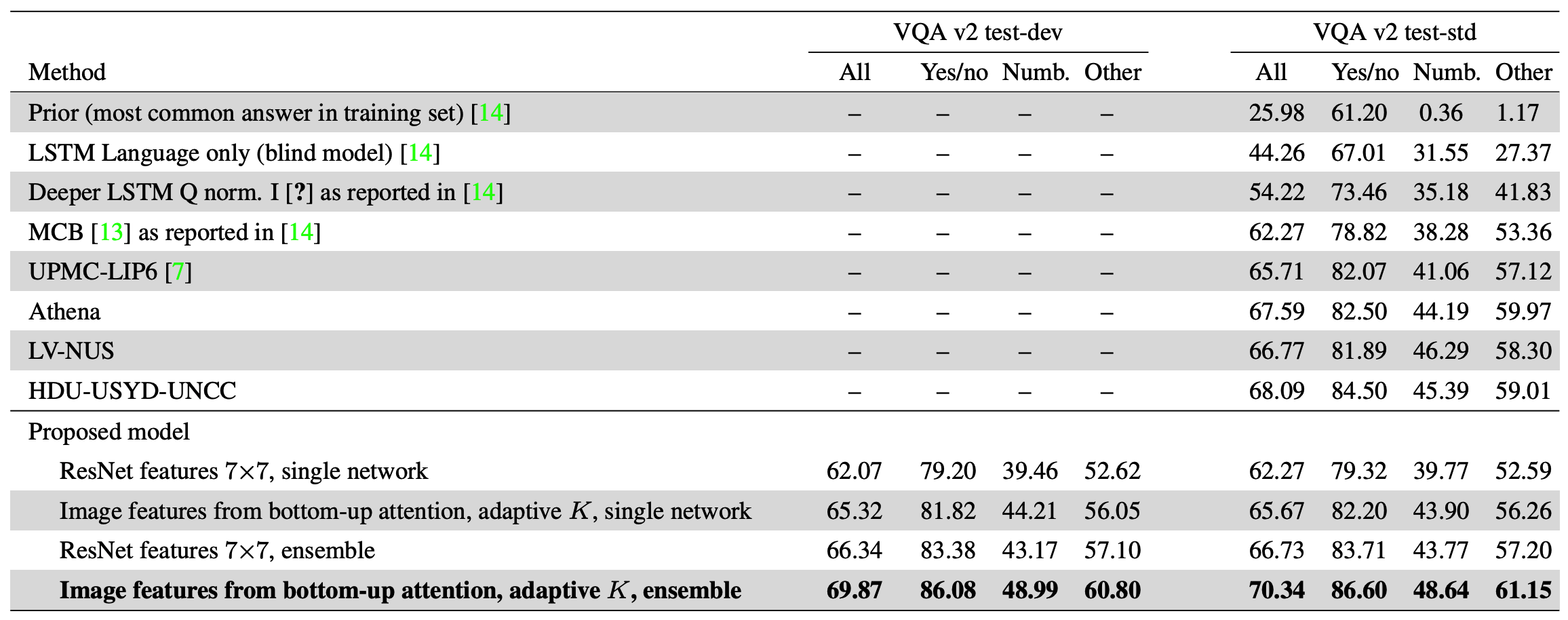
This paper achieved the best result on 2017 VQA challenge.

Rejoice in what you learn and spray it!