Generating Sentences from a Continuous Space
WHY?
기존의 언어모델(RNNLM)은 문장을 만들 때 한 단어씩 만들어야 하며 문장의 정보를 가지고 있는 latent representation의 정보를 활용하지 못한다.
WHAT?
이 논문에서는 문장의 정보를 함축한 latent representation을 나타내기 위하여 인코더, 디코더에 sequential model을 활용한 VAE를 사용한다. 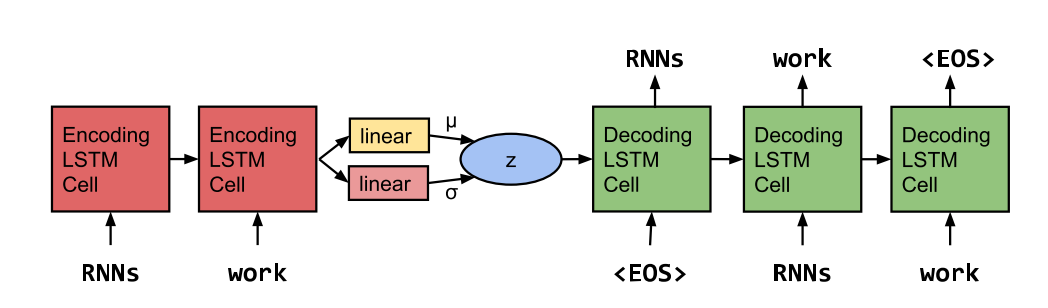 하지만 종종 sequential model을 디코더로 사용할 경우 디코더가 문장의 정보를 함축한 latent representation을 활용하지 않는 posterior collapse현상이 일어난다. 이를 극복하기 위하여 두 가지 트릭을 사용하는데 첫번째는 KL cost annealing으로 KL에 주어진 가중치를 0으로 부터 시작하여 점점 올리는 방법을 사용한다. 이를 통하여 encoder가 좀더 풍부한 정보를 담도록 유도할 수 있다. 두번째는 word dropout과 historyless decoding방법으로 decoder를 약화시키는 방법이다. 보통 학습할 때 ground truth데이터를 활용하는데 word dropout은 이 데이터의 일부를 임의로 제거하는 방법이다. 이를 통하여 decoder가 강제로 latent variable에 의존하도록 만든다.
하지만 종종 sequential model을 디코더로 사용할 경우 디코더가 문장의 정보를 함축한 latent representation을 활용하지 않는 posterior collapse현상이 일어난다. 이를 극복하기 위하여 두 가지 트릭을 사용하는데 첫번째는 KL cost annealing으로 KL에 주어진 가중치를 0으로 부터 시작하여 점점 올리는 방법을 사용한다. 이를 통하여 encoder가 좀더 풍부한 정보를 담도록 유도할 수 있다. 두번째는 word dropout과 historyless decoding방법으로 decoder를 약화시키는 방법이다. 보통 학습할 때 ground truth데이터를 활용하는데 word dropout은 이 데이터의 일부를 임의로 제거하는 방법이다. 이를 통하여 decoder가 강제로 latent variable에 의존하도록 만든다.
So?
이를 통하여 word imputation task에서 정성적으로 좋은 결과를 거두었으며 adversarial classifier를 활용한 정량적 결과로도 좋은 성능을 보였다. 또한 sentence의 latent representation도 유의미한 정보를 담고 있는 것을 확인할 수 있었다.
Critic
sentence의 latent representation이 구체적으로 어떠한 정보를 담고 있는지 모호한 것 같다. 이 latent representation가 내포하고 있는 global structure를 좀더 살펴보면 좋을 것 같다.

Rejoice in what you learn and spray it!