Distributed Prioritized Experience Replay
WHY?
Gorila framework separated several actors and learners with a centralized parameter server to parrallelize the learning process. This framework required one GPU per learner.
WHAT?
Ape-X architecture only consists of two parts: many actors and one learner. Given a model from model, many actors generate experience simultaneously. The learner collects all the experience from actors to a centralized experience replay and train the model constantly with experience sampled from experience replay. 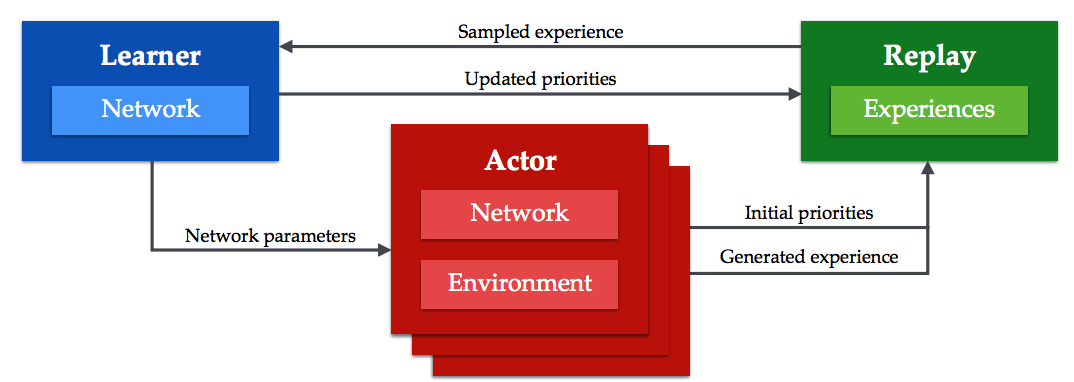 Among huge amount of experience to learn from, Ape-X prioritizes the samples with td-error. Since actors calculate the possible max value for a state when selecting a action, td-errors can be calculated from actors without any additional computation. In Ape-X DQN, actors with different
Among huge amount of experience to learn from, Ape-X prioritizes the samples with td-error. Since actors calculate the possible max value for a state when selecting a action, td-errors can be calculated from actors without any additional computation. In Ape-X DQN, actors with different \epsilon-greedy policy would collect differet kinds of experience. Algorithm is as follows. 
So?
The efficiency of training scaled with actors resulting enormous improvement in both result and speed.
Critic
Interestingly, this structure is exactly the same structure that I implemented to Alphachu since I only had one GPU. This paper came out in March, but I implemented it at April before I read this paper several days ago. Except for the efficient calculation of the priority from actors, everything is exactly the same including varying epsilon. On one hand I feel a little bit sorry to miss the chance to write a great paper, but I also feel proud for thinking about the great idea all by myself.

Rejoice in what you learn and spray it!