GQA: A New Dataset for Real-World Visual Reasoning ans compositional Question Answering
WHY?
There were some problems in previous VQA dataset. Strong language prior, non-compositional language and variablility in language were key obstacles for model to learn proper concepts and logics from VQA dataset. Synthetically generated CLEVR dataset solved these problems to some extent but lacked realisticity by remaining in relatively simple domain.
WHAT?
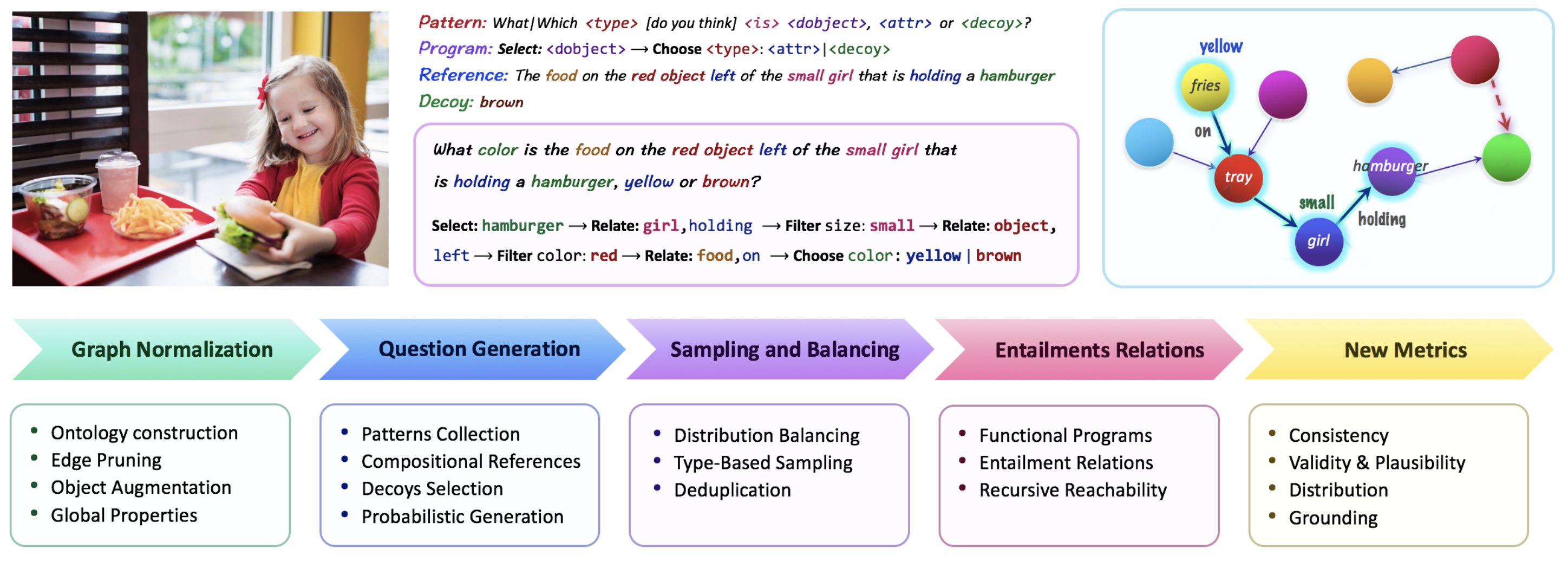
GQA dataset enhanced the VQA dataset by adopting the methodology of CLEVR dataset. GQA dataset starts with Visual Genome scene graphs dataset. This paper augments the VG scene graph by cleaning up the language of graphs, pruning the edge of graphs and utilizing the object detector. Question engine build questions from scene graph with 274 structural patterns, object references and decoys by traversing the graphs. Each question pattern is related with a functional representation. With semantic program, the questions are balanced in two granulaity levels. Through these process, GQA dataset resulted 113,018 images with 22,669,678 questions in total with vocab size of 3097 for questions, and 1878 for answers. Also this dataset provide additional metrics other than accuracy such as consistency, validity, plausibility and distribution.
So?
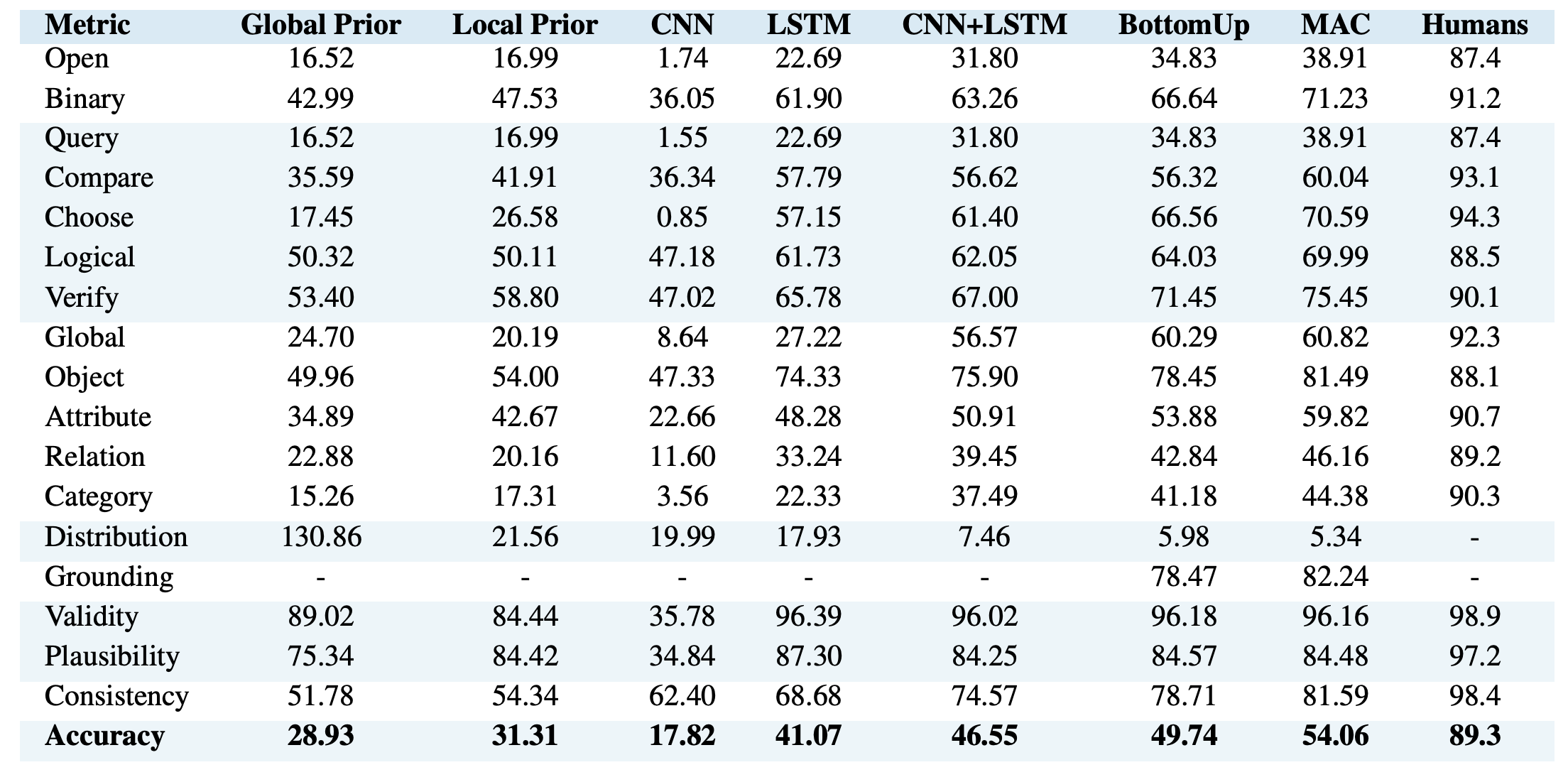
This dataset provided reasonable criteria for visual reasoning models which reflects reality.

Rejoice in what you learn and spray it!