FiLM: Visual Reasoning with a General Conditioning Layer
in Studies on Deep Learning, Computer Vision
WHY?
There are some architectures for relational reasoning but lacks general-purpose components for relational reasoning and visual question answering.
WHAT?
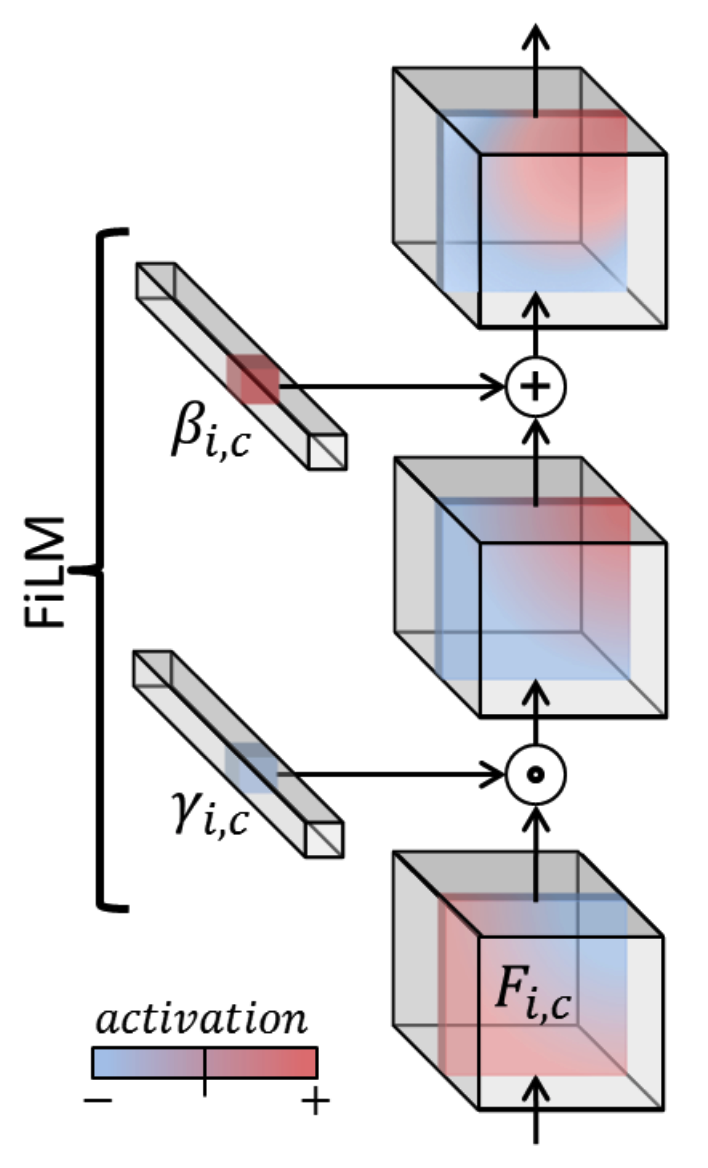
This paper propose Feature-wise Linear Modulation(FiLM) to conditionally focus on the image. By linearly transforming the output of convolution filter, FiLM conditionally choose certain filters.
\gamma_{i,c} = f_c(x_i)\\
\beta_{i,c} = h_c(x_i)\\
FiLM(F_{i,c}|\gamma_{i,c}, \beta_{i,c}) = \gamma_{i,c} F_{i,c} + \beta_{i,c}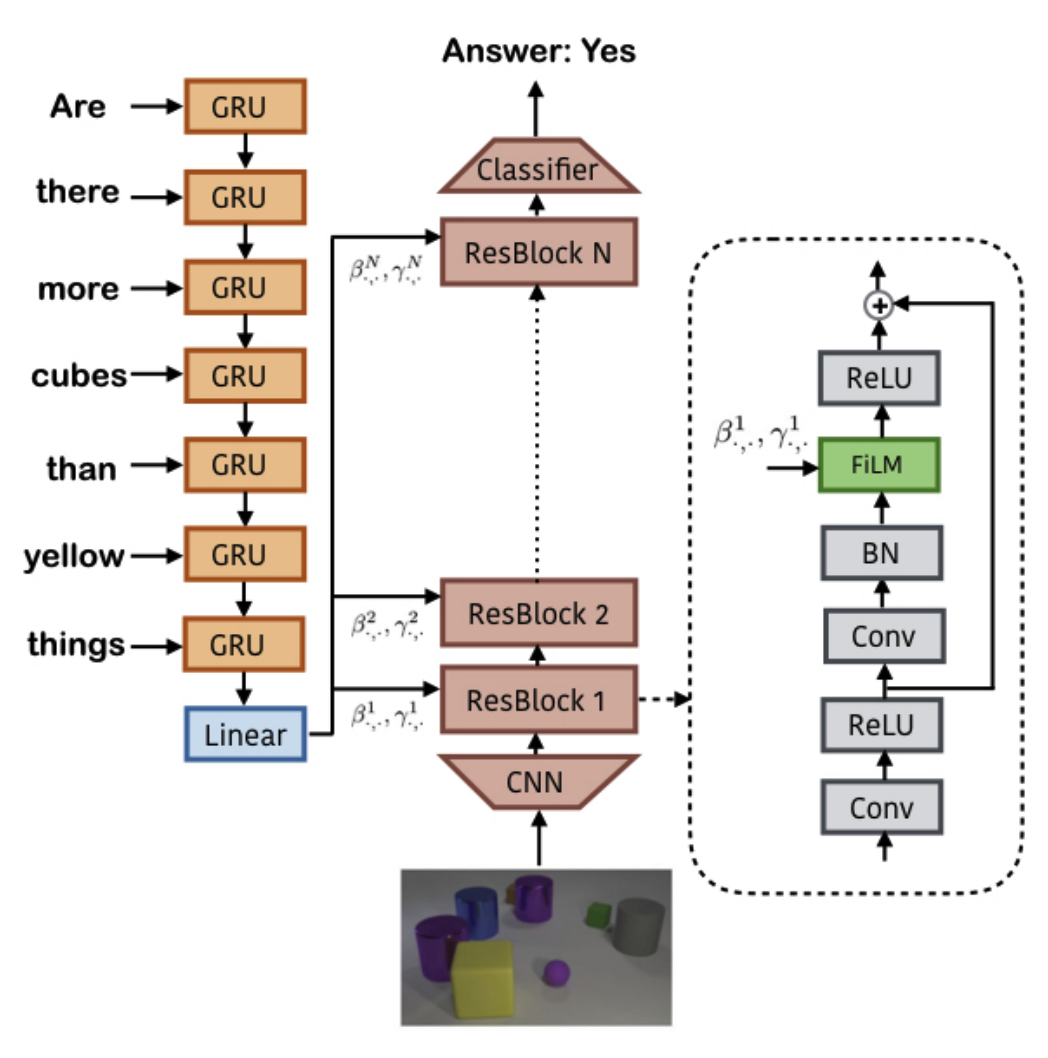
FiLM generator takes questions as input and output betas and gammas for each ResBlocks. Each ResBlock contains FiLM after convolution and BN layer. Several ResBlocks with FiLM stacks to form FiLM-ed network.
So?
 FiLM not only achieved the state of the art result in CLEVR, but also showen to conditionally focus on the image based on queries.
FiLM not only achieved the state of the art result in CLEVR, but also showen to conditionally focus on the image based on queries.

Rejoice in what you learn and spray it!