Compositional Attention Networks for Machine Reasoning
WHY?
Previous methods for visual reasoning lacked interpretability. This paper suggests MAC network which is fully differentiable and interpretable attention based visual reasoning model.
WHAT?
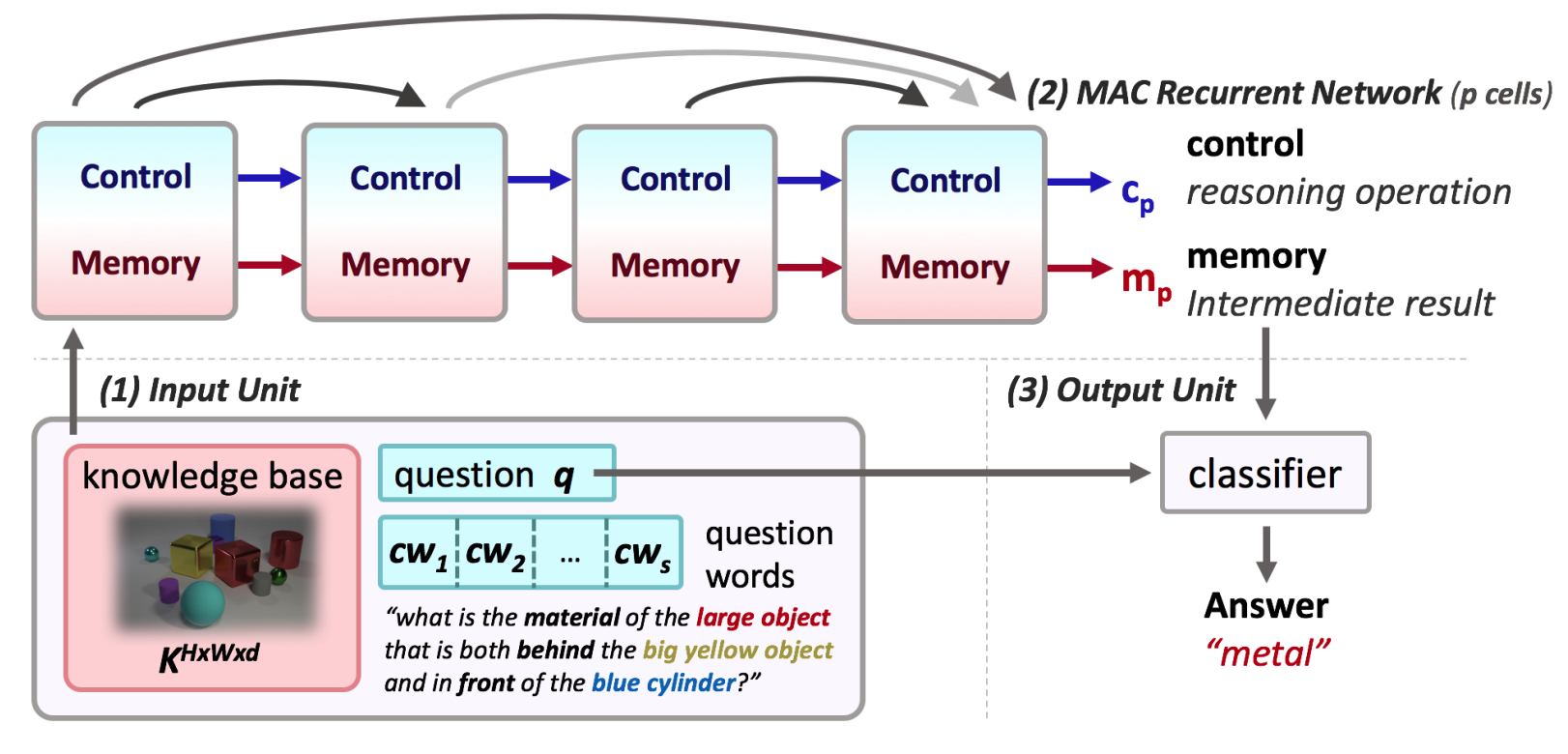
MAC network consists of three parts: the input unit, the MAC cells, and the read unit. The input unit encodes the question and the image. The word embeddings of question is processed by d-dimensional biLSTM. The hidden states of the model are contextual representation for each word. The concatenation of the last hidden state of backward, and forward LSTM is used as a question representation. This question representaion is linearly projected to vectors for each reasoning step. For image features, the conv4 layer output of pretrained ResNet101 is used. Image features are called knowledge base in this paper.
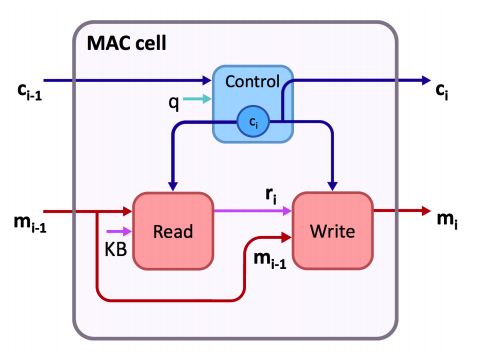
Recurrent Memory, Attention, and Composition cell(MAC cell) is newly designed recurrent cell for reasoning operation. p number of MAC cells are stacked to perform multiple reasoning steps. MAC cells have two hidden states: control(c_i) and memory(m_i). The control state represents the reasoning operation and the memory state holds intermediate information.
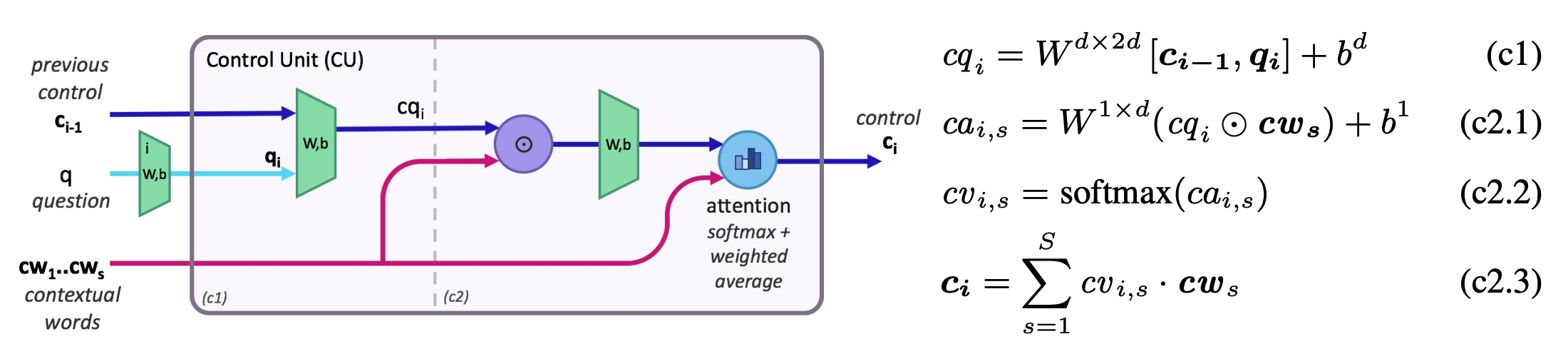
The control unit updates the control state. New control state is a soft attention-based weighted average of the question words based on the question vector for each step.
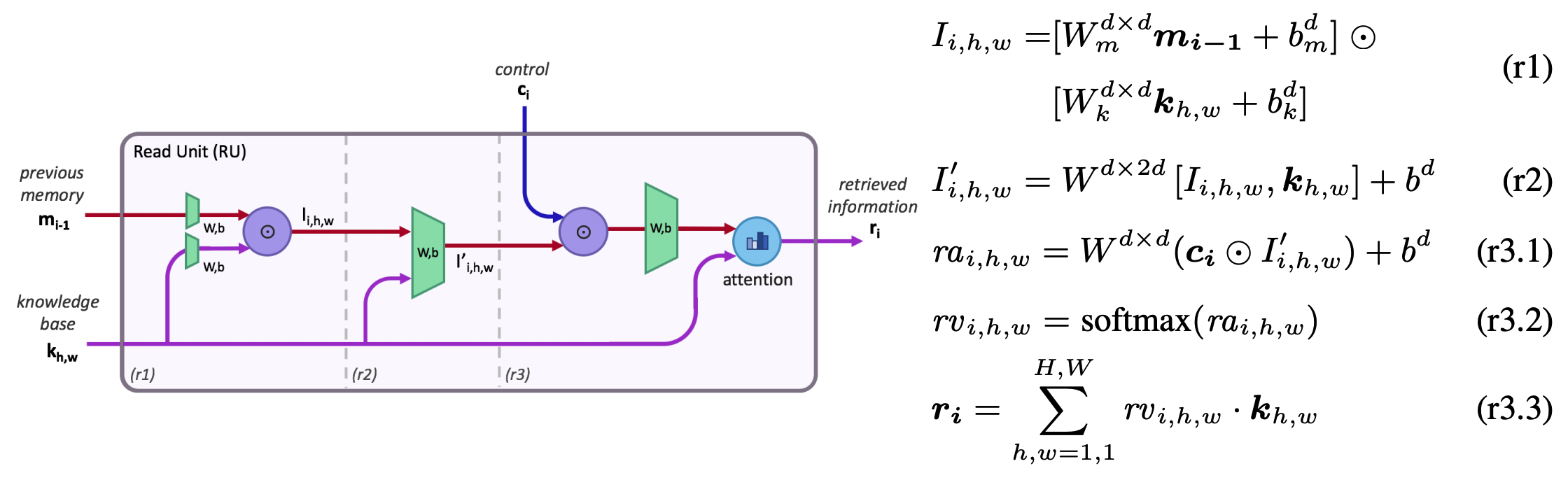
The read unit extracts information from memory. The interaction of memory and image features(I) and independent facts(k) are concatenated to produce information(I’). The information(I’) interacts with control units(c_i) to produce weights(rv). The knowledge bases are weighted averaged to produce the read unit(r_i).
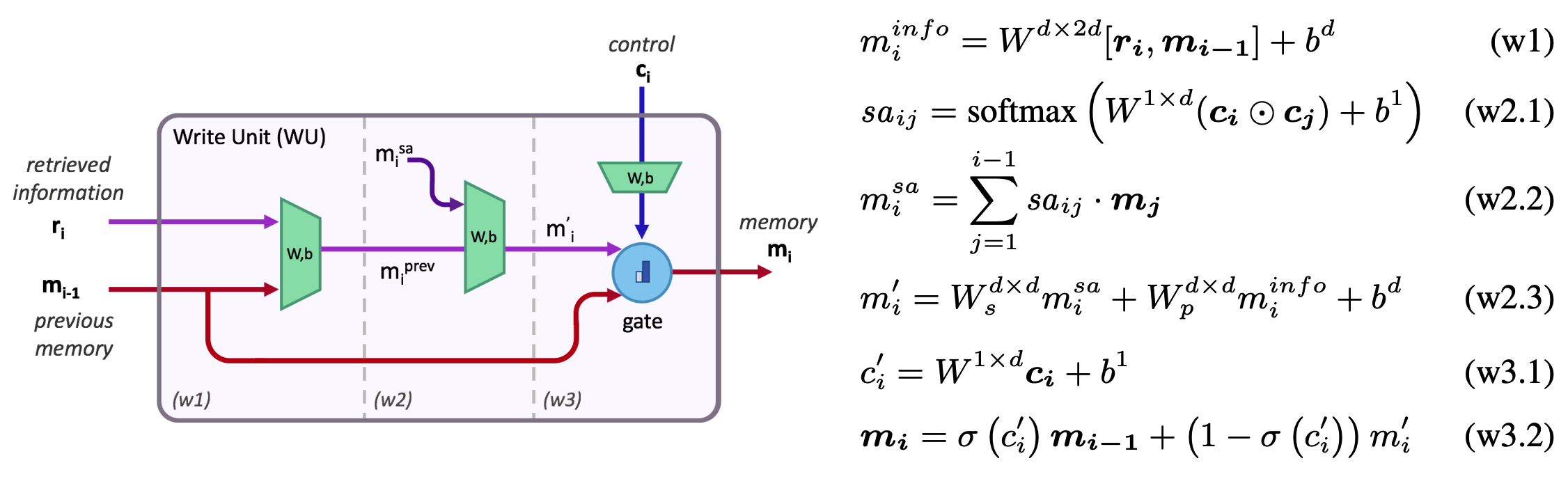
The memory unit is updated based on the retrieved read unit and previous memory. There are two ways that the control unit controls the write operation: one is performing self attention and the other is to be used as memory gate.
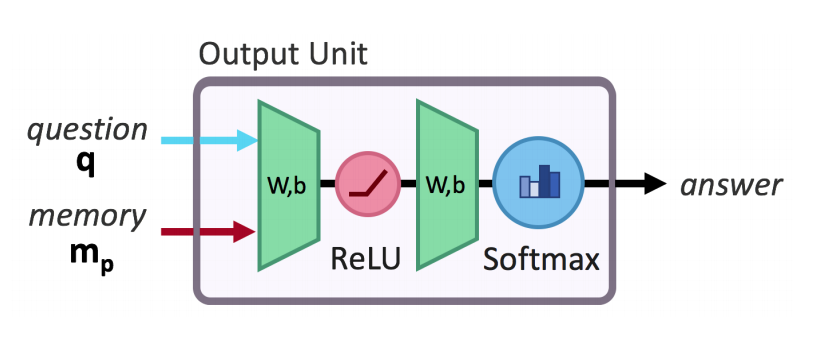
The question representation(q) and the final memory state(m_p) are used as input for 2-layer-fc softmax classifier to result the answer.
So?
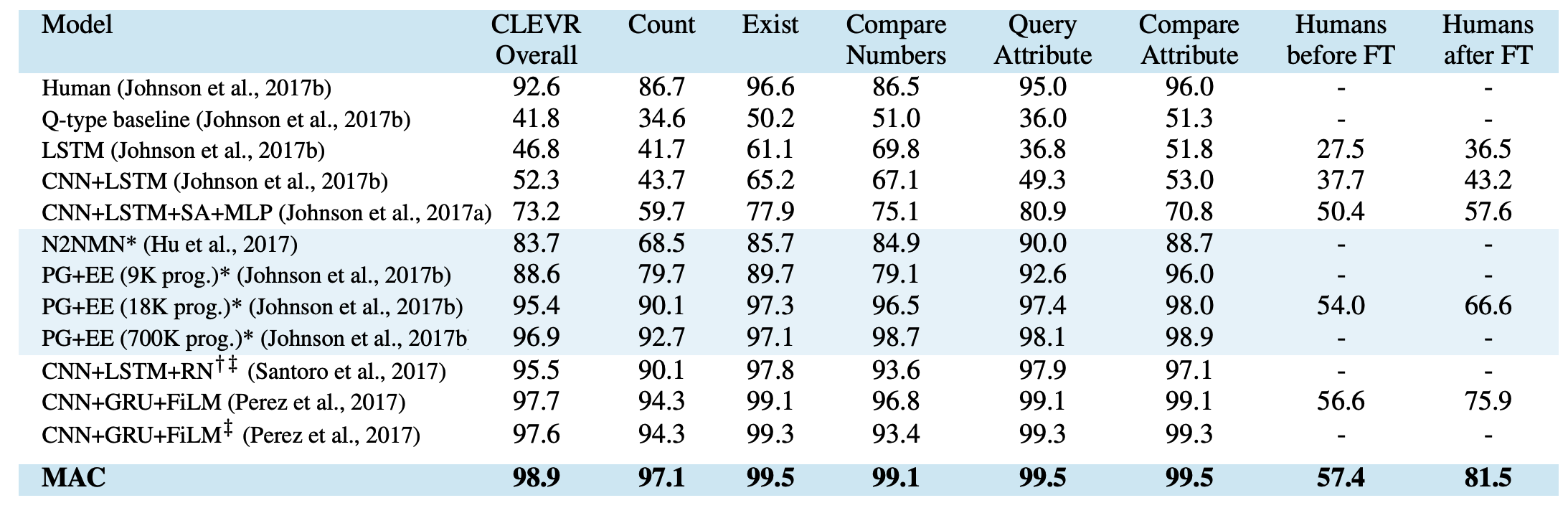
MAC showed the state-of-the-art result on both Clevr and Clevr-Humans without using information about data generation.

Also, the attention map of MAC showed that this model is properly solving the task.

Rejoice in what you learn and spray it!