A Deep Generative Model for Disentangled Representations of Sequential Data
WHY?
Video나 Audio와 같은 sequential data로 부터 time-dependent feature(dynamics)와 time independent feature(content)를 구분하는데 성공하였다.
WHAT?
Generative model은 다음과 같다.
p_{\theta}(x_{1:T}, z_{1:T}, f) = p_{\theta}(f)\Pi^T_{t=1} p_{\theta}(z_t|z_{< t})p_{\theta}(x_t|z_t, f)
Inference model은 VAE를 base로 한다.
max_{\theta, \phi}E_{p_D(x_{1:T})}[E_{q_{\phi}}[log \frac{p_{\theta}(x_{1:T}, z_{1:T},f)}{q_{\phi}(z_{1:T}, f|x_{1:T})}]]
q의 factorisation 방식에 따라 두 가지 모델을 제시한다. 첫번째 방식은 “factorised q”라고 부른다.
q_{\phi}(z_{1:T}, f|x_{1:T}) = q_{\phi}(f|x_{1:T})\Pi_{t=1}^T q_{\phi}(z_t|x_t)
두번째 모델은 “full q”라고 부른다. q_{\phi}(z_{1:T}, f|x_{1:T}) = q_{\phi}(f|x_{1:T})q_{\phi}(z_{1:T}|f, x_{1:T})
이 두 모델의 차이점은 “full q”는 z의 생성이 그 이전의 x에만 의존하는 것이 아니라 전체 sequence에 대하여 의존한다는 것이다. 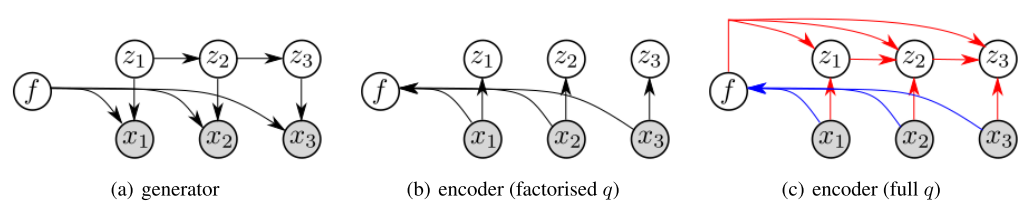 이 모델은 bidirectional LSTM을 통하여 구현이 가능하다.
이 모델은 bidirectional LSTM을 통하여 구현이 가능하다.
So?
latent variable의 disentangle여부를 시험하기 위하여 Unconditional generation, conditional generation, feature swapping을 시험하였다.  Sprits 데이터 셋에서 행동을 sequence마다 다르게 하여 time-dependent feature로 설정하고 피부, 머리, 상의, 하의의 조합을 통한 캐릭터의 identitiy를 time-independent feature로 설정한다. 그 결과 dynamics/content가 잘 분리된 것을 확인할 수 있었다.
Sprits 데이터 셋에서 행동을 sequence마다 다르게 하여 time-dependent feature로 설정하고 피부, 머리, 상의, 하의의 조합을 통한 캐릭터의 identitiy를 time-independent feature로 설정한다. 그 결과 dynamics/content가 잘 분리된 것을 확인할 수 있었다.
Critic
FHVAE와 매우 유사한 것 같다. 그리고 캐릭터 행동의 sequence를 video라고 볼 수 있을 지 의문이다.

Rejoice in what you learn and spray it!