World Models
WHY?
Instead of instantly responding to incoming stimulus, having a model of environment to make some level of prediction would help perform in reinforcement learning.
WHAT?
Agent model of this paper consists of three parts: Vision(V), Memory(M), and Controller(C). 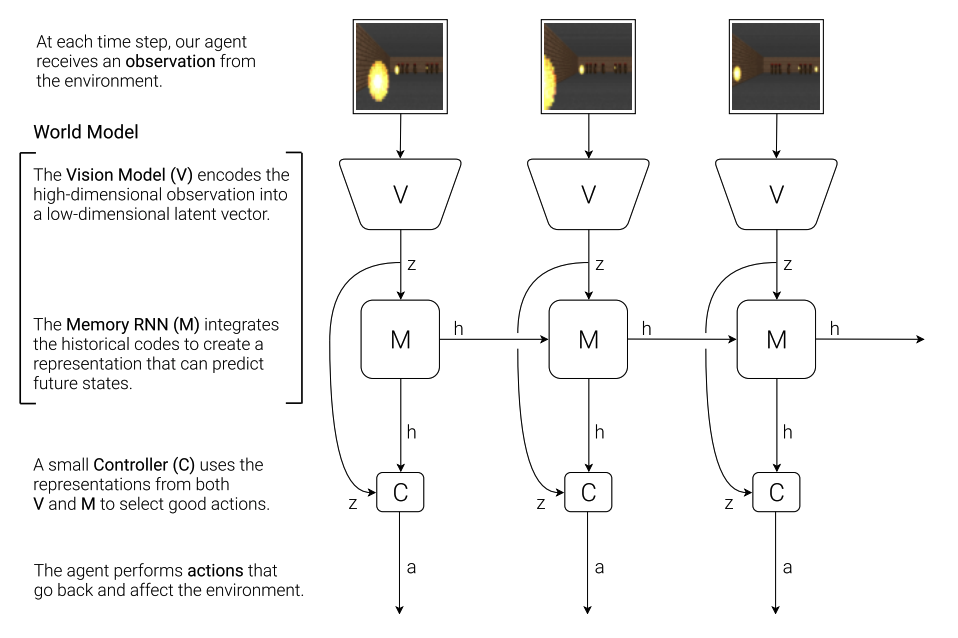 Since simulating the whole pixels of environment is inefficient, VAE model is used to compress the essential information of the environment. For memory, mixture density network with a rnn(MDN-RNN) is used to predict the next state given current state and action. Since we only use latent variables of the images, controller model can be small as a simple FNN. FNN takes latent variables of V and hidden layer of M as input and output action. Since the number of parameters is small, this paper used evolution strategies(Covariance-Matrix Adaptation Evolution Strategy: CMA-ES) to train controller. M and C are pretrained with randomized agent. Roll-out algorithm is as follows.
Since simulating the whole pixels of environment is inefficient, VAE model is used to compress the essential information of the environment. For memory, mixture density network with a rnn(MDN-RNN) is used to predict the next state given current state and action. Since we only use latent variables of the images, controller model can be small as a simple FNN. FNN takes latent variables of V and hidden layer of M as input and output action. Since the number of parameters is small, this paper used evolution strategies(Covariance-Matrix Adaptation Evolution Strategy: CMA-ES) to train controller. M and C are pretrained with randomized agent. Roll-out algorithm is as follows.
 Iterative process of exploring the environment and training the model enables the model to navigate the environment.
Iterative process of exploring the environment and training the model enables the model to navigate the environment.
So?
The model achieved state of the art result in CarRacing of Atari and VizDoom.
Critic
Idea of incorporating prediction of the future into rl model seems great. Though I’m not very familiar with evolution strategy, I think there would be ways to corporate this model to traditional rl model.
Ha, David, and Jürgen Schmidhuber. “World Models.” arXiv preprint arXiv:1803.10122 (2018).

Rejoice in what you learn and spray it!