Categorical Reparameterization with Gunbel-Softmax
in Studies on Deep Learning, Deep Learning
WHY?
The same motivation with Concrete.
WHAT?
Gumbel-Softmax distribution is the same as Concrete distribution. GS distribution appoaches to on-hot as temperature goes 0. 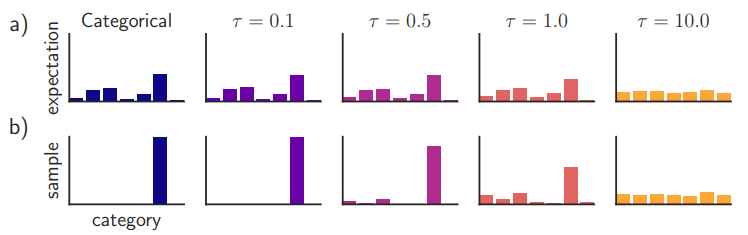 However, GS samples are not exactly the same as categorical samples resulting bias. This GS estimator becomes close to unbiased but the variance of gradient increase (trade-off). If we do not replace categorical variables with GS variables, we can estimate the gradient with Straight-Through GS estimator.
However, GS samples are not exactly the same as categorical samples resulting bias. This GS estimator becomes close to unbiased but the variance of gradient increase (trade-off). If we do not replace categorical variables with GS variables, we can estimate the gradient with Straight-Through GS estimator. 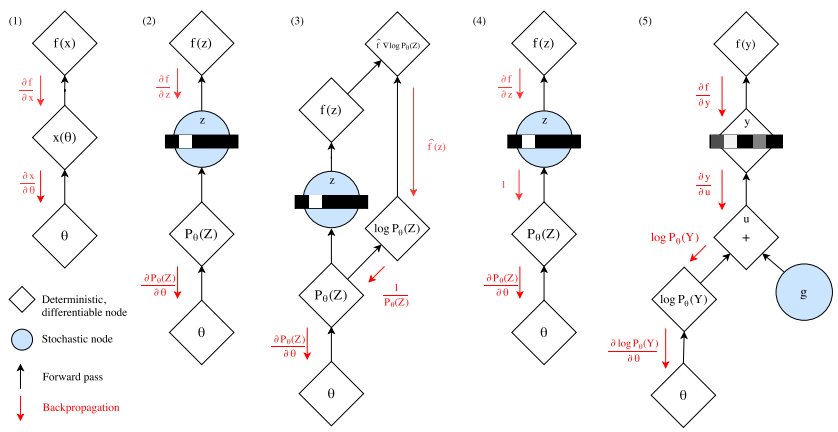 (3) is score function estimator, (4) is Straight-Through estimator and (5) is GS estimator (pathwise derivative).
(3) is score function estimator, (4) is Straight-Through estimator and (5) is GS estimator (pathwise derivative).
So?
GS outperformed in generation of MNIST images in NLL. ST-GS outperformed previous approach in semi-supervised classification.
Critic
Nice visualization. I wonder how this can be used in NLP.

Rejoice in what you learn and spray it!