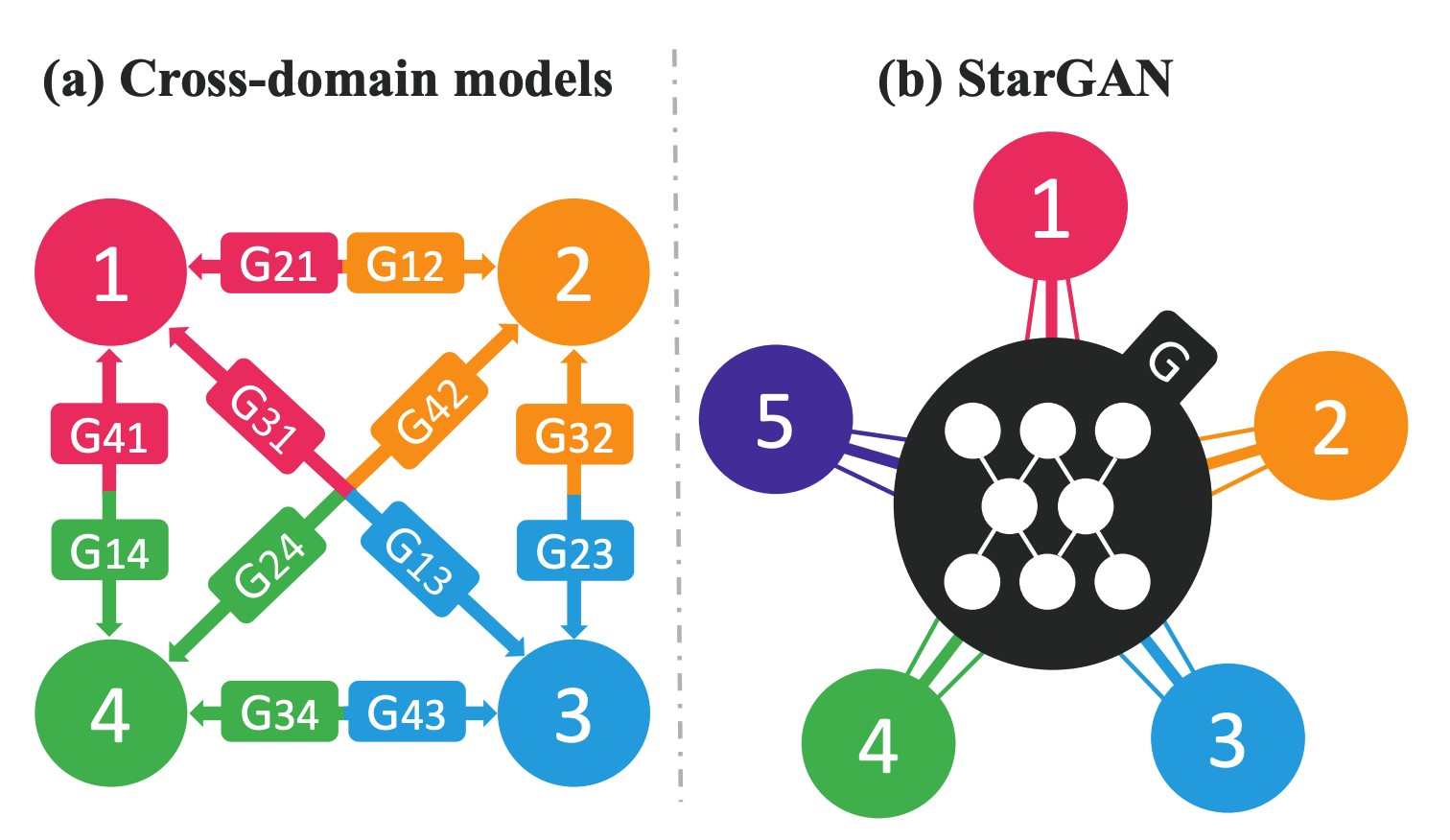
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
WHY?
High quality disentangled generation of images has been the goal for all the generative models. This paper suggests style-based generator architecture for GAN with techniques borrowed from the field of style transfer.
Choosing an appropriate prior is important for VAE. This paper suggests two-layered VAE with flexible VampPrior.
Generating a high resolution image with GAN is difficult despite of recent advances. This paper suggests BigGAN which adds few tricks on previous model to generate large scale images without progressively growing the network.
Training GAN on high-resolution images is known to be difficult.
\beta-VAE is known to disentangle latent variables.
Autoregressive model has been dominant model for density estimation. On the other hand, various non-linear transformations techniques enabled tracking of density after transformation of variables. Transformation Autoregressive Networks(TAN) combined non-linear transformation into autoregressive model to capture more complicated density of data.
Two approximation methods, Variational inference and MCMC, have different advantages: usually, variational inference is fast while MCMC is more accurate.
Generative models of discrete data with particular structure (grammar) often result invalid outputs. Grammar Variational Autoencoder(GVAE) forces the decoder of VAE to result only valid outputs.
VAE can learn useful representation while GAN can sample sharp images.
Learning directed generative model is difficult.
GAN had troble modeling the entire image.
Recent variational training requires sampling of the variational posterior to estimate gradient. NVIL estimator suggest a method to estimate the gradient of the loss function wrt parameters. Since score function estimator is known to have high variance, baseline is used as variance reduction technique. However, this technique is insufficient to reduce variance in multi-sample setting as in IWAE.
The largest drawback of training Generative Adversarial Network (GAN) is its instability. Especially, the power of discriminator greatly affect the performance of GAN. This paper suggests to weaken the discriminator by restricting the functional space of it to stablize the training.
This paper wanted to disentangle the label related and label unrelated information from data. The model of this paper is simpler and more effective than that of Disentangling Factors of Variation in Deep Representations Using Adversarial Training.
Directed latent variable models are known to be difficult to train at large scale because posterior distribution is intractable.
Estimating the distribution of data can help solving various predictive taskes. Approximately three approaches are available: Directed graphical models, undirected graphical models, and density estimation using autoregressive models and feed-forward neural network (NADE).
The motivation is almost the same as that of NICE, and RealNVP.
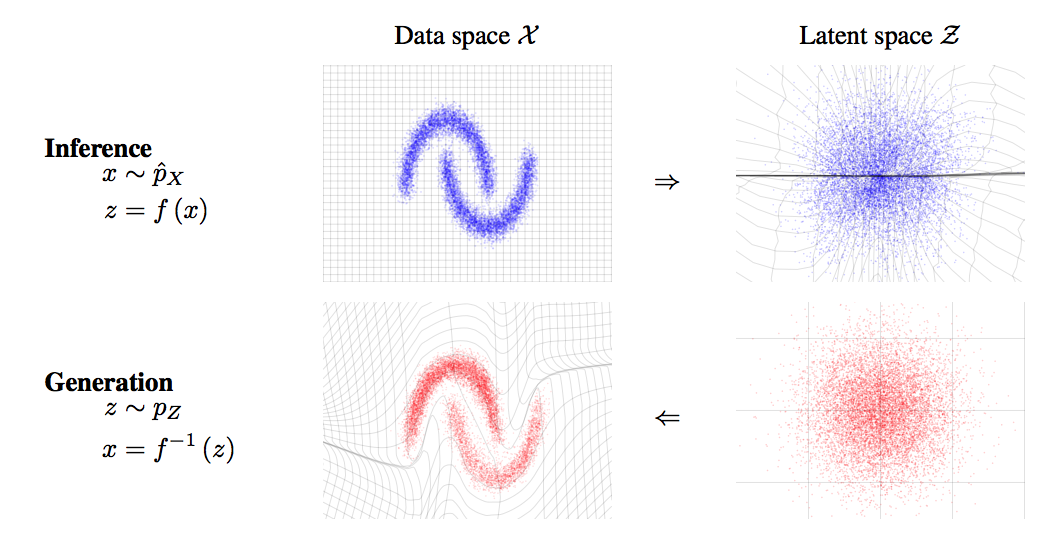 The motivation is almost the same as that of NICE. This papaer suggest more elaborate transformation to represent complex data.
The motivation is almost the same as that of NICE. This papaer suggest more elaborate transformation to represent complex data.
Modeling data with known probability distribution has a lot of advantages. We can exactly calculate the log likelihood of the data and easily sample new data from distribution. However, finding tractable transformation of data into probability distribution or vice versa is difficult. For instance, a neural encoder is a common way to transform data but its log-likelihood is known to be intractable and another separately trained decoder is required to sample data.
This paper wanted to catch non-linear dynamics of the object in video.
Most of deep directed latent variable models including VAE try to maximize the marginal likelihood by maximizing the Evidence Lower Bound(ELBO). However, marginal likelihood is not sufficient to represent the performance of the model.
In VAE framework, the quality of the generation relies on the expressiveness of inference model. Restricting hidden variables to Gaussian distribution with KL divergence limits the expressiveness of the model.
VAE구조를 활용하여 semi-superviesd training을 할 때 label정보를 활용하여 label에 관한 정보와 그 외의 정보를 disentangle하고자 한다.
VAE의 구조의 latent variable을 사용하여 sequence를 reconstruct하려는 시도는 많았다. 하지만 decoder가 너무 강력해서 latent variable을 무시하는 ‘Posterior Collapse’현상이 많이 일어나서 긴 sequence의 정보를 가진 latent variable을 구성하긴 힘들었다.

Video나 Audio와 같은 sequential data로 부터 time-dependent feature(dynamics)와 time independent feature(content)를 구분하는데 성공하였다.
사람의 눈은 그림을 볼 때 한번에 보는 것이 아니라 시선에 따라 부분적으로 본다.
Independently Controllable Factors에서는 agent가 environment와의 상호작용을 통하여 control가능한 factor들을 학습할 수 있었다. 하지만 uncontrollable한 factor는 인식하지 못한다는 단점이 있었다.
NN모델들은 이미지를 인식/분류할 때 계층적 특징들을 학습한다. 하지만 Generative model들은 계층적으로 생성하지 않는다. Stacked Hierarchy를 가지고 있는 HVAE(Hierarchical VAE)같은 경우는 계층적인 구조를 가지고 있지만 각 층이 계층적인 특징을 학습하지 못한다. 마지막 층(Bottom layer)에 정보가 충분하여 마지막 층만 사용하여 이미지를 reconstruct할 수 있다. 하지만 마지막 층만 사용한다면 unimodal하기 때문에 multimodal한 구조를 잡지 못하고 특징들은 disentangle되지 못한다.
VAE는 generation에 상당히 강력한 도구이지만 conditional stochastic variable을 통하여 생성하기 때문에 계층적인 특징을 학습하는 깊은 모델을 만들기 어렵다.
기존의 이미지에 대한 Disentangling은 static한 이미지에 대하여 이루어져 왔다. 하지만 강화 학습의 프레임웍에서 에이전트가 환경과 상호작용을 한다면 자신의 행동에 대한 독립적인 변화 요인들을 추출할 수 있을 것이다.
실제 세상은 물리나 화학과 같은 몇 가지 일관적인 규칙으로 부터 무한히 다양한 형태가 나온다. 이러한 규칙들은 추상화를 통하여 개념으로 나타날 수 있으며 이러한 개념들의 계층과 조합을 통하여 지수적으로 많은 개념을 만들어낸다.
\beta-VAE는 최근 disentangling에서 좋은 성과를 거두고 있지만 이에 대하여 깊이있는 이해가 되고 있지는 않다.
Image의 representation을 interpretable하게 만든다면 원하는 이미지를 생성해낼 수 있을 것이다.
Semi-supervised learning이란 적은 양의 labeled 데이터로 부터 정보를 효과적으로 generalize하여 많은 양의 unlabeled 데이터의 정보를 활용하고 이를 통하여 모델의 성능을 향상시키는 학습을 말한다.
Disentanling과정은 기본적으로 x내에서 독립적인 요소를 찾아 각각 다른 z로 나누는 작업이다. 이를 위하여 z의 prior를 independent Gaussian(N(1,0))로 간주하여 근사하거나(Beta-VAE) Batch내의 z의 값을 permutation하여 adversarial training하는 방법으로 독립을 유도하였다(FVAE). 하지만 Beta-VAE는 모든 관측치의 분포를 N(1,0)으로 강제하여 관측치의 차이에 덜 민감하게 만들어 reconstruction의 성능이 떨어진다.
Beta-VAE에서는 q(z|x)와 p(z)의 KL divergence에 추가적인 penalty를 줌으로서 z간의 독립성을 유도하여 disentangling을 이루었다. 하지만 기존의 vae보다 reconstruction 성능이 떨어지는 결과가 나타났다.
기존의 autoencoder는 이미지나 음성과 같은 연속형 데이터에 대한 latent structure를 잘 잡았지만 텍스트와 같은 discrete한 데이터의 latent structure를 잡는 것은 어려웠다.
이미지에 대한 unsupervised disentangling의 시도는 많았지만 오디오와 같은 sequential data에서의 unsupervised disentangling의 시도는 많지 않았다.
unsupervised하게 이미지를 source domain에서 target domain으로 보내는 것을 image to image translation이라고 한다. 기존의 방법들은 이렇게 다른 도메인으로 mapping하는 방법이 deterministic하다고 간주하여 왔기 때문에 다양한 이미지를 생성할 수 없었다.
기존의 implicit generative model(VAE)들은 hierarchical latent codes를 통하여 데이터의 statistics를 학습할 수 있지만 decoder를 통한 sampling만 가능하고 likelihood function은 tractable하지 않다. 반대로 likelihood function을 학습할 수 있는 autoregressive neural networks(NADE, MADE, PixelCNN)들은 likelihood function을 학습할 수 있는 대신 latent codes를 활용하지 못한다.
기존의 conditional gan에서는 hidden representation에 class의 정보를 concate하고 그에 맞는 이미지가 형성되길 바라는 방법 밖에 없었다. 이 방법은 단순한 이미지를 형성할 때는 괜찮지만 복잡한 이미지를 만들기는 힘들었다.
한 이미지가 가진 정보에서 label이 가지는 정보와 그 외의 정보로 나뉠 수 있다. 이 두 정보를 분리하여 추출할 때 이에 대한 supervision이 있다면 추출하기가 쉽겠지만 현실 데이터에서는 한계가 있다.
기존의 neural autoregressive model(RNN, MADE, PixelRNN/CNN)들은 VAE의 decoder로서 부적합하다고 여겨져왔다. 왜냐하면 이 모델들의 표현력이 너무 강력해서 종종 latent variable들을 무시하고 이미지를 생성했기 때문이다.
기존의 VAE는 latent variable들의 aggregated posterior를 특정 분포를 따르게 하기 위하여 KL Divergence의 regularizer를 사용한다.
기존의 WaveNet은 음성 데이터의 학습은 빠른 반면 Sampling(Generation)은 순차적으로 이루어져야 하기 때문에 매우 속도가 느렸다.
이미지들 간의 style을 뽑아내기 위해서는 같은 모습에 대하여 다른 스타일이 적용되어 있는 이미지들이 pairing되어야 한다.
Normializing flow는 posterior를 유연하게 가정하기 위하여 x를 변환시킨다. 이때 변환은 가역적이어야 하고 determinant를 구하기 쉬워야 한다.
MADE나 PixelCNN/RNN과 같은 autoregressive한 neural density estimator들은 좋은 성과를 보여왔다.
Normalizing Flow를 사용하면 Planar/radial flow나 inverse Autoregressive Flow와 같은 특정한 변환에 한해서는 빠르게 Density evaluation을 할 수 있어 variational inference에 유용하게 사용되었다. 하지만 새로운 데이터들에 대해서는 효율적으로 계산하기가 어렵기 때문에 density estimation에는 적합하지 않았다.
단순 Autoencoder에서는 x내에 특정 구조를 가정하지 않는다.
Variational Inference를 할때 다루기 쉬운 형태의 posterior함수 q를 가정하고 이를 실제 분포에 근사한다. 하지만 posterior를 쉬운 형태로 가정하기 때문에 실제 분포에 잘 근사되지 않는 것과 같은 한계가 존재한다.
PixelRNN에서 제안되었던 PixelCNN은 함께 제안되었던 다른 구조와는 달리 유연하고 병렬화가 가능하여 계산적으로 효율적이며 성능 또한 뛰어났다.
VAE에서 추출하는 latent variable들은 기본적으로 continuous하다. 하지만 언어와 같이 discrete환경에서는 discrete한 latent variable들이 필요하기도 하다.
PixelRNN에서는 LSTM을 활용하여 distribution으로부터 auto-regressive한 구조를 추출할 수 있었다.
이미지의 generation을 위해서 density를 추정해야하는데 이는 매우 어려운 일이다.
기존의 VAE에서는 variational lower bound를 통하여 marginal log-likelihood E_{P_{X}}[log_{P_{G}}(X)를 최대화 하고 Q(z)와 P(z|x)간의 KL Divergence를 최소화하도록 하는 regularization term을 통하여 encoder와 decoder를 학습시켰다.
기존의 GAN을 통하여 이미지를 생성할 때 이미지의 특성에 대한 조건을 부여할 수 없었다.
기존의 대표적인 Generation Model로 VAE와 GAN이 있다. VAE는 목적 분포를 직접 구하는 대신 계산 가능한 다른 분포를 가정하고 이와 목적 분포와의 거리(KL Divergence)를 최소화 함으로써 간접적으로 목적 분포를 구하였다. 하지만 KL Divergence는 두 함수의 support가 같은 영역에서 정의가 되어있어야 한다는 한계가 있다. 또한 GAN은 목적 분포를 직접 구하지 않고도 Discriminator loss를 통하여 표본을 생성하지만 discriminator와 generator간의 학습 비율이 중요하고 섬세하여 학습이 어렵다는 단점이 있다.
오토인코더는 분포 p(x)를 축소하여 latent variable z로 요약한 뒤 이를 재구성한 것과 원래의 데이터의 차이를 최소한으로 하도록 인코더와 디코더를 학습한다. 이 결과 z를 통하여 x의 가장 중요한 특징들을 요약하길 바란다.
이미지의 피쳐를 추출할 때, 한 피쳐 값이 이미지에 대하여 우리가 인지할 수 있는 특성을 나타낸다면 이 값을 조정하여 이미지를 의도적으로 생성할 수 있을 것이다. 이렇게 이미지의 feature를 우리가 의도한 방식으로 추출하는 것을 disentangling이라고 한다. 이러한 disentangled factors는 이미지의 특성 및 추상화된 개념을 나타내게 된다.

Rejoice in what you learn and spray it!