Deep Contextualized Word Representations
WHY?
Former word representations such as Word2Vec or GloVe didn’t contained linguistic context.
Former word representations such as Word2Vec or GloVe didn’t contained linguistic context.
Directed latent variable models are known to be difficult to train at large scale because posterior distribution is intractable.
Estimating the distribution of data can help solving various predictive taskes. Approximately three approaches are available: Directed graphical models, undirected graphical models, and density estimation using autoregressive models and feed-forward neural network (NADE).
The motivation is almost the same as that of NICE, and RealNVP.
All the previous neural machine translators are based on word-level translation. Word-level translators has critical problem of out-of-vocabulary error.
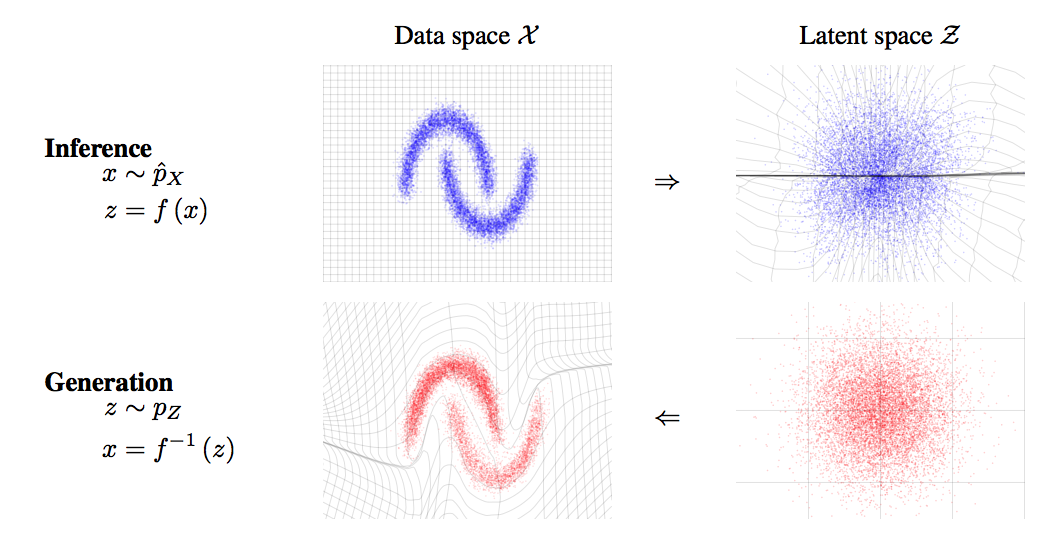 The motivation is almost the same as that of NICE. This papaer suggest more elaborate transformation to represent complex data.
The motivation is almost the same as that of NICE. This papaer suggest more elaborate transformation to represent complex data.
Modeling data with known probability distribution has a lot of advantages. We can exactly calculate the log likelihood of the data and easily sample new data from distribution. However, finding tractable transformation of data into probability distribution or vice versa is difficult. For instance, a neural encoder is a common way to transform data but its log-likelihood is known to be intractable and another separately trained decoder is required to sample data.
in Studies on Deep Learning, Deep Learning
The same motivation with Concrete.

Rejoice in what you learn and spray it!