Apache Hadoop YARN: Yet Another Resource Negotiator
Summary
Apache Hadoop is widely used not only for MapReduce jobs but also any kinds of data processing. The first version of Hadoop had 3 critical drawbacks. First, the framework is hard-coded to MapReduce only. Second, the slots for map and reduce functions are static limiting utilization. Third, JobTracker managed all the task processes so that the framework is not scaleable and vulnerable to failure of JobTracker. Apach Hadoop YARN is a new resource manager that separates resource managing and task scheduling. 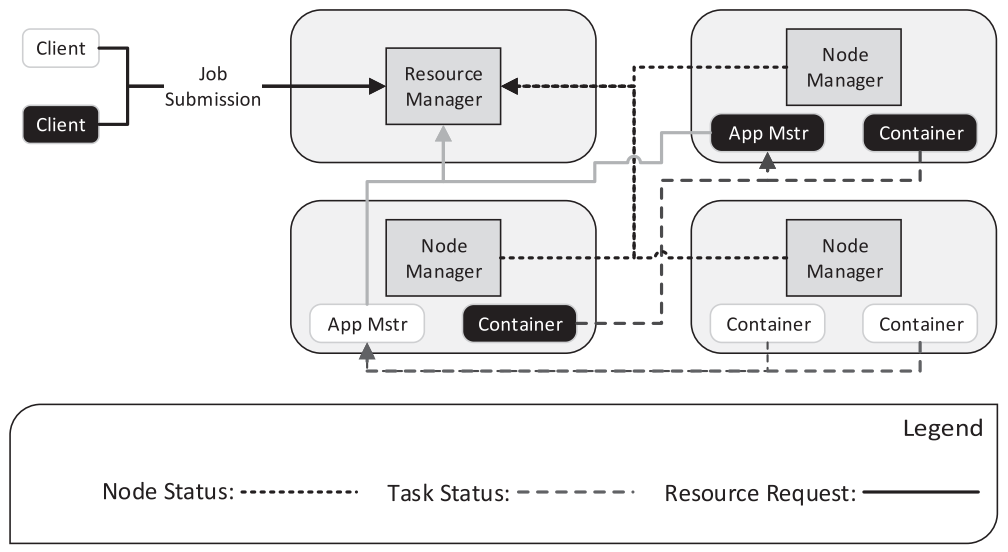 Resource Manager(RM) receives jobs from client and allocate leases of resources(containers). RM comminicates with Node Manager(NM) which manage the resources of a particular node. Accepted jobs are managed by scheduler inside RM, and RM assigns Application Manager(AM) in a node to coordinate application’s execution in the cluster. RM and AM also communicates through heartbeat protocol.
Resource Manager(RM) receives jobs from client and allocate leases of resources(containers). RM comminicates with Node Manager(NM) which manage the resources of a particular node. Accepted jobs are managed by scheduler inside RM, and RM assigns Application Manager(AM) in a node to coordinate application’s execution in the cluster. RM and AM also communicates through heartbeat protocol.
Strengths
More scalable and robust distributed scheduling is possible.
Weaknesses
I assume that communication cost and resources used by AM are tradeoff for robustness.
New things I learned
I only thought distributed scheduling would increase scalability, but didn’t think it also increases robustness.
Discussion topics
Would YARN be efficient to many small jobs?

Rejoice in what you learn and spray it!