MapReduce: Simplified Data Processing on Large Clusters
Summary
MapReduce is a programming model that parallelize the computation on large data. 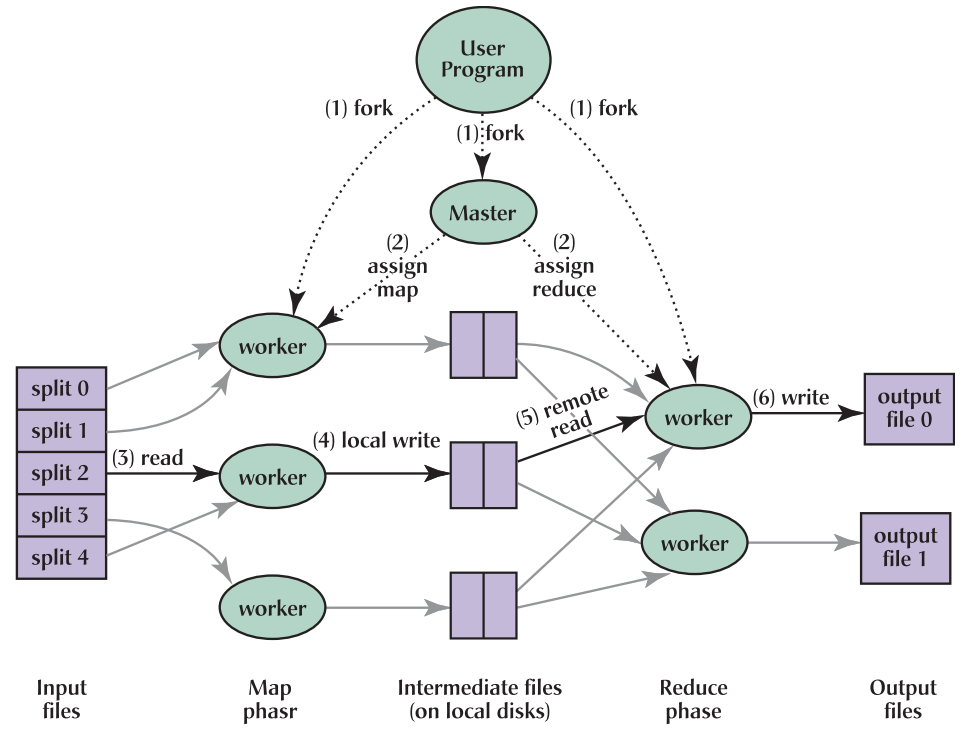 The computation consists of two functions: a map and a reduce function. First, input data are partitioned into M splits. Map function takes a partition of inputs and produce a set of intermediate key/value pairs. By partitioning the key space(hash(key mod R)), the result can be split into R pieces. Intermediate pairs can be stored in R regions of local disk. Reduce function accesses the local disks of the map workers and groups intermediate pairs with the same key. The master coordinate the location and size of intermediate file regions.
The computation consists of two functions: a map and a reduce function. First, input data are partitioned into M splits. Map function takes a partition of inputs and produce a set of intermediate key/value pairs. By partitioning the key space(hash(key mod R)), the result can be split into R pieces. Intermediate pairs can be stored in R regions of local disk. Reduce function accesses the local disks of the map workers and groups intermediate pairs with the same key. The master coordinate the location and size of intermediate file regions. 
Strengths
Massively parallellized computation is possible.
Weaknesses
In this paper, MapReduce is defined with on job. But increasing number of jobs and their communication would cause complexity.
New things I learned
I didn’t know master coordinate the communication and backup tasks can be performed to increase robustness.
Discussion topics
What kinds of operations can be framed as map/reduce and what kinds of them cannot?

Rejoice in what you learn and spray it!