BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding
WHY?
Former Transformer was unidirectional language model.
WHAT?
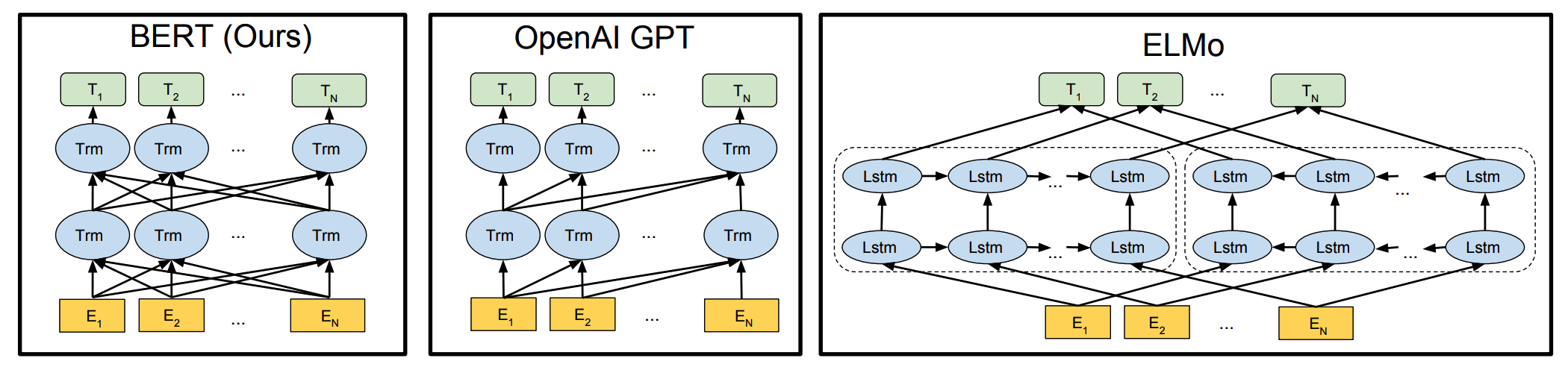
BERT is multi-layer bidirectional Transformer encoder.
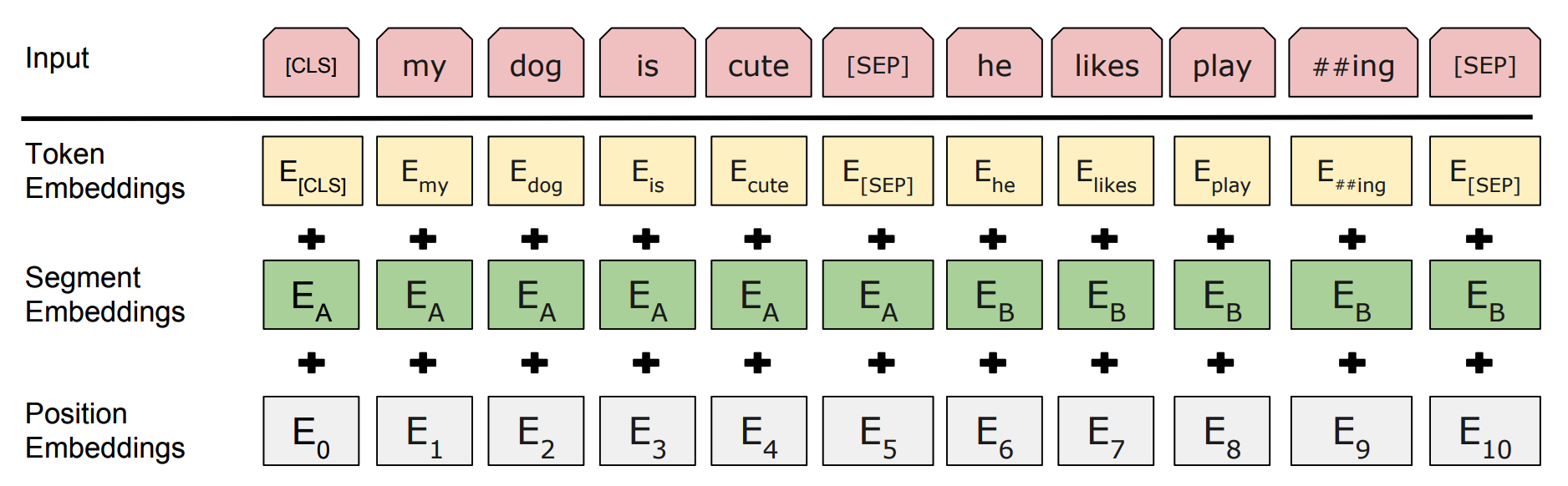
A sequence of input representation can be either a single text sentence or a pair of text sentences. The first token of every sequence is a classification token and sentences in a sequence are separated by a separation token. Each token in the sequence is the sum of three components: Token embeddings, segment embeddings and position embeddings. Two sentences in a sequence is differentiated again by segment embeddings.
Two kinds of pretraining tasks are used for BERT. Since BERT is bidirectional, masked language modeling task is used. Mased LM randomly choose words in the corpus and replace with mask token and the hidden vector of the mask token is used for the softmax. BERT randomly choose 15% of the tokens. 80% of the chosen words are turn into mask tokens. 10% are replaced with a random word and the rest 10% are kept unchanged. The second task is next sentence prediction task. The training loss is the sum of the mean masked LM likelihood and mean next sentence prediction likelihood.
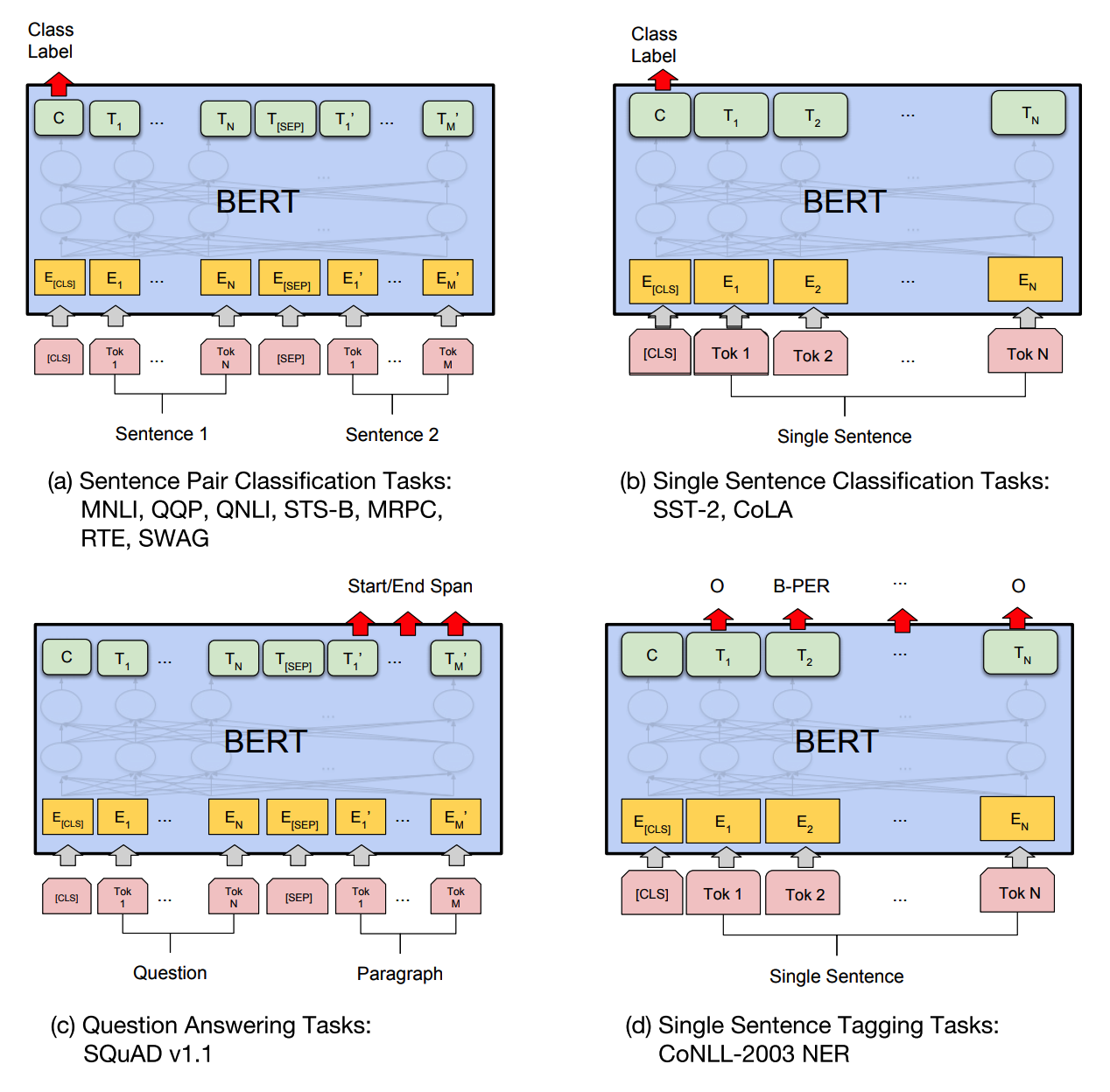
Fine-tuning for each task can be differ. Sentence level classification task only need a W matrix that can be multiplied to classification token. Start and end vector is trained to estimate the span in question answering task. A classifier is trained to classify each token in named entity recognition task.
So?
BERT achieved State-Of-The-Art result in nearly every language task including GLUE datasets, SQUAD dataset, named-entity recognition task, and SWAG dataset with a single model. Broad ablation study is conducted to prove the effectiveness of BERT.
Critic
No argument on the incredible result, but I’m not sure what BERT is doing. Works on interpretability can be useful to examine whether BERT is actually solving the task.

Rejoice in what you learn and spray it!