Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
in Studies on Deep Learning, Deep Learning
WHY?
Most VQA reasoning algorithms are not transparent in their reasoning and not robust to complex reasoning.
WHAT?
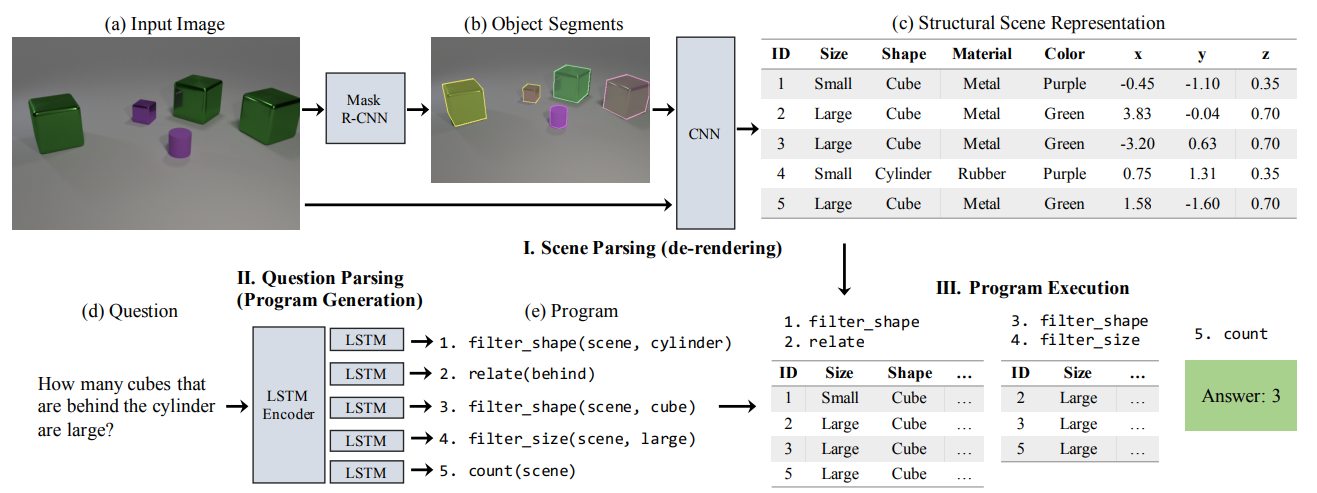 This paper combined two different methods: deep representation learning and symbolic program execution. Neural Symbolic VQA consists of three stages: scene parsing, question parsing and program execution. In scene parsing stage, Mask R-CNN is used to segment objects from input image. And then, CNN is used on original input image and segmented image to classify properties of the objects(size, shape and material etc) to form structural scene representation. In question parsing stage, LSTM encoder with attention is used to parse question into a series of programs. Each output of LSTM is classified into one of pre-defined modules(filter_shape, relate, and count etc). Finally, the program is performed on the structural scene representation to answer the question. Mapping of natural languate question into a sequence of programs requires new dataset, but this paper solved this problem in semi-supervised manner with few labels and REINFORCE algorithm.
This paper combined two different methods: deep representation learning and symbolic program execution. Neural Symbolic VQA consists of three stages: scene parsing, question parsing and program execution. In scene parsing stage, Mask R-CNN is used to segment objects from input image. And then, CNN is used on original input image and segmented image to classify properties of the objects(size, shape and material etc) to form structural scene representation. In question parsing stage, LSTM encoder with attention is used to parse question into a series of programs. Each output of LSTM is classified into one of pre-defined modules(filter_shape, relate, and count etc). Finally, the program is performed on the structural scene representation to answer the question. Mapping of natural languate question into a sequence of programs requires new dataset, but this paper solved this problem in semi-supervised manner with few labels and REINFORCE algorithm.
So?
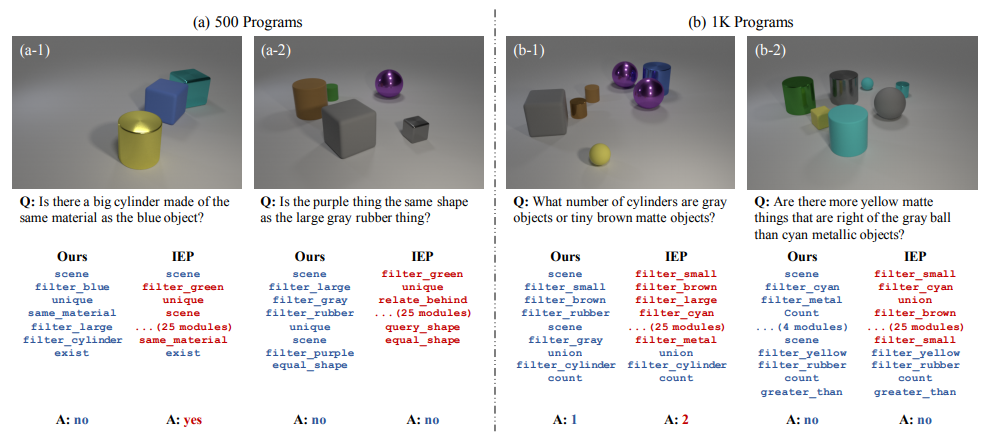 NS-VQA achieved almost perfect score on CLEVR datasets. This model is not only fully transparent, but also data and memory efficient.
NS-VQA achieved almost perfect score on CLEVR datasets. This model is not only fully transparent, but also data and memory efficient.
Critic
Split the task into several sub-tasks and assign the best neural network module for each sub-task. Absolutely brilliant!

Rejoice in what you learn and spray it!