Scalable Distributed DNN Training Using Commodity GPU Cloud Computing
WHY?
Synchronization is an important issue is distributed SGD. Too few synchoronization among nodes causes unstable training while too frequent synchoronization causes high communication cost.
WHAT?
This paper tried to reduce the communication cost of distributed SGD drastically by compression. This paper suggests two points. First is that many techniques that accelerate the SGD utilize delayed weights update including mini-batching. Second is that sub-gradients are usually very small.
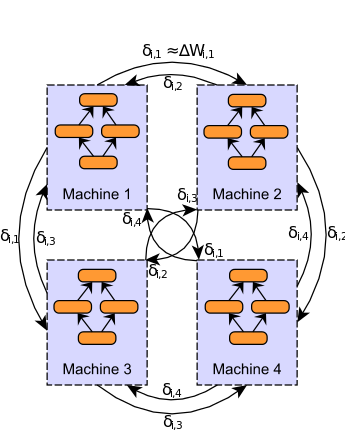
Based on the observations, sub-gradients can be compressed drastically by thresholding absolute value of the gradient. Then, the number of parameters that need to be updated is small enough to keep them in key-value pair. In addition, gradients that does not exceed the threshold are not abandoned, but rather accmulated as gradient residual. The gradient information can be further compressed with 1-bit quantization. By reducing the cost of communication dramatically, all nodes can communicate with all other nodes which enable fast synchronication without the need for parameter server. This method can be used for both model-parallelizaion and data-parallelizaion. Pseudo-code is as follows.
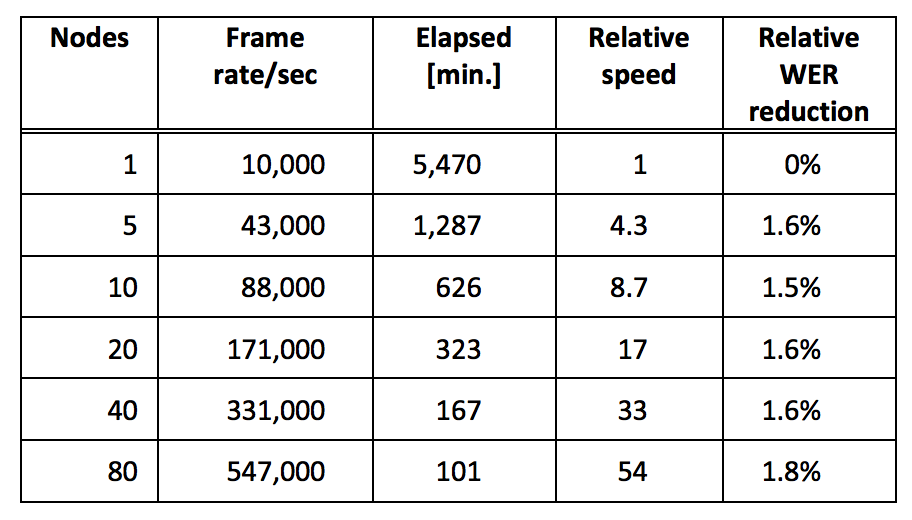 Source: Skymid
Source: Skymid
So?
This method succeeded in shortening training time linearly and make better preformance with cluster computing.
Critic
New approch to distributed deep learning!

Rejoice in what you learn and spray it!