Large Scale Distributed Deep Networks
WHY?
Models with huge number of parameters or huge amount of data do not fit in GPU memory of a machine.
WHAT?
This paper introduces DistBelief which is a software framework that enable parallel training in cluster settings. There are two kinds of parallelism in training deep-learning model: Model parallelism and data parallelism. Model parallelism is used when the number of parameters is too large for a machine to train. DistBelief split the parameters into multiple machines and in charge of communication between machines.
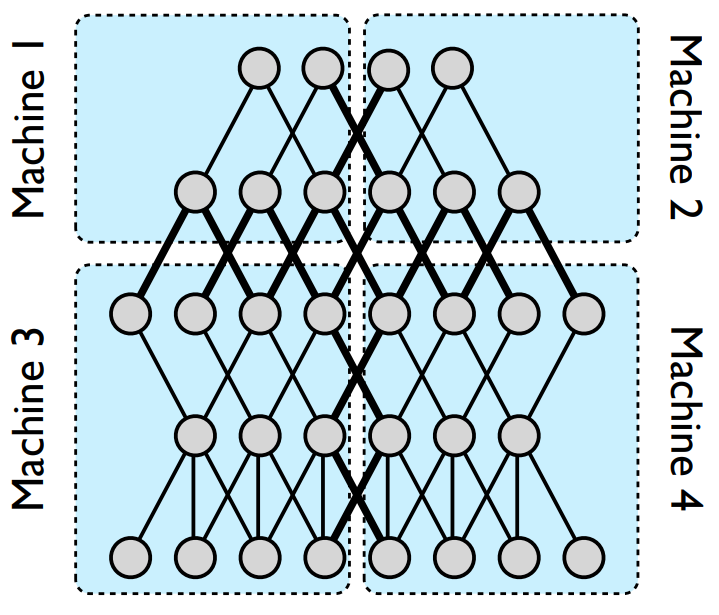
Data parallelism is used when dataset is too big or we want to hasten the training. DistBelief provides two kinds of optimization procedures: Downpour SGD and Sandblaster L-BFGS.
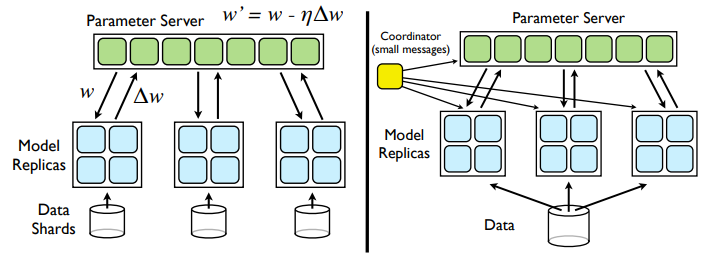
Downpour SGD makes a parameter server and multiple replicas of model to multiple machines. Each model in machines accumalate gradient with partitioned set of data. All of the machines send calculated gradient to parameter server and receive updated model every n mini-batch(synchronize). Adaptive optimization such as Adagrad is known to work well with Downpour SGD. Sandblaster L-BFGS implement L-BFGS with a coordinator coordinate the training with messages.
So?
Model parallelism was effective to model with larger parameter number. Data parallelism showed faster and better training than single GPU.
Critic
Suggested framework for distributed deep-learning but lack of theoratical analysis.

Rejoice in what you learn and spray it!