A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation
WHY?
All the previous neural machine translators are based on word-level translation. Word-level translators has critical problem of out-of-vocabulary error.
WHAT?
This paper suggest Bi-Scale recurrent neural network with attention to model character level translator. Input are encoded into BPE. 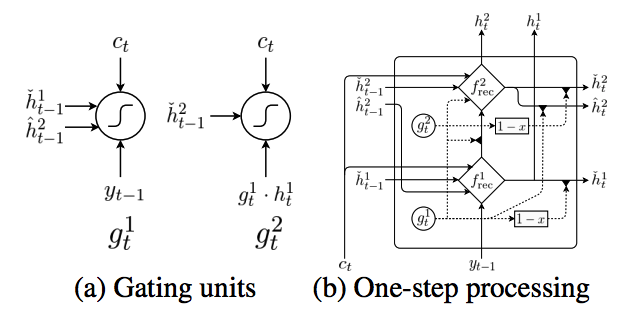 Slower layer carries information of word and faster layer carries information of character. Architecturally, slower layer can update only faster layer finish a word, resulting slower layer updates slower.
Slower layer carries information of word and faster layer carries information of character. Architecturally, slower layer can update only faster layer finish a word, resulting slower layer updates slower. h^1 is faster layer and h^2 is slower layer. 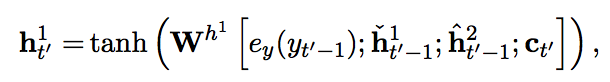
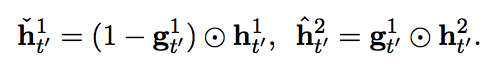
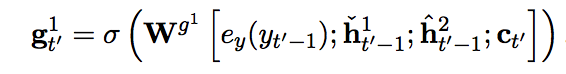
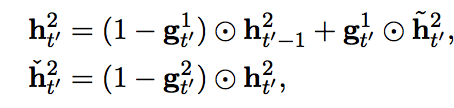
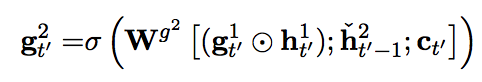
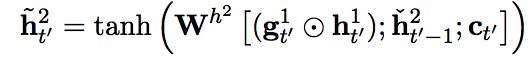
So?
 CL nmt showed better result than traditional non-neural translator and showed attention functioning properly.
CL nmt showed better result than traditional non-neural translator and showed attention functioning properly.
Critic
One attempt to make rnn capture hierarchical structure. Result seems quite disappointing.

Rejoice in what you learn and spray it!