Hierarchical Variational Autoencoders for Music
WHY?
VAE의 구조의 latent variable을 사용하여 sequence를 reconstruct하려는 시도는 많았다. 하지만 decoder가 너무 강력해서 latent variable을 무시하는 ‘Posterior Collapse’현상이 많이 일어나서 긴 sequence의 정보를 가진 latent variable을 구성하긴 힘들었다.
WHAT?
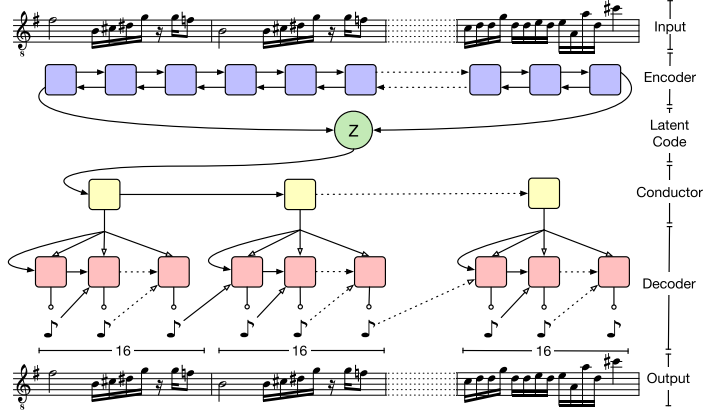 이 모델은 모델링하려는 sequence의 길이에 따라 바뀐다. 여기에서는 2마디, 32마디, 16마디의 구조를 가지고 실험하였다. 이 모델의 encoder는 간단한 bidirectional LSTM이다(2048 * 2). 각 방향의 output들이 concatenate되어 linear layer를 지난다(1024). 이 중의 반은 mu, 반은 logvar로 배정되어 512차원의 latent variable distribution을 정의한다. 32마디를 reconstruct하려는 경우 디코더는 2층 1024 hidden state를 가진 LSTM 2개가 사용된다. 위에서 추출한 latent variable은 첫번째 decoder의 initial state로 들어가 순서대로 512차원의 임베딩 벡터 16개를 추출한다. 이 16개의 embedding vector는 각각 두번째 decoder의 initial state로 들어가서 각각 32개의 음을 130개의 선택지로 부터 선택하여 만든다. 이 때 각 순간의 output음은 주어진 embedding과 concatenate되어 다음 input으로 들어가며 teacher forcing 대신 scheduled sampling을 사용하였다.
이 모델은 모델링하려는 sequence의 길이에 따라 바뀐다. 여기에서는 2마디, 32마디, 16마디의 구조를 가지고 실험하였다. 이 모델의 encoder는 간단한 bidirectional LSTM이다(2048 * 2). 각 방향의 output들이 concatenate되어 linear layer를 지난다(1024). 이 중의 반은 mu, 반은 logvar로 배정되어 512차원의 latent variable distribution을 정의한다. 32마디를 reconstruct하려는 경우 디코더는 2층 1024 hidden state를 가진 LSTM 2개가 사용된다. 위에서 추출한 latent variable은 첫번째 decoder의 initial state로 들어가 순서대로 512차원의 임베딩 벡터 16개를 추출한다. 이 16개의 embedding vector는 각각 두번째 decoder의 initial state로 들어가서 각각 32개의 음을 130개의 선택지로 부터 선택하여 만든다. 이 때 각 순간의 output음은 주어진 embedding과 concatenate되어 다음 input으로 들어가며 teacher forcing 대신 scheduled sampling을 사용하였다.
So?
2-bar Drum, 2-bar Melody, 32-bar Melody, 16-bar Trio(Lead, Bass, Drum)에 대하여 reconstruct과 다음 음 예측을 압도적으로 잘 해내었다.
Critic
상당히 직접적인 방법으로 hierarchy를 표현하였는데 성능이 좋아 놀랍다. 이러한 hierarchy를 generalize하여 정교한 모델을 만들 수 있을 것 같다.

Rejoice in what you learn and spray it!