Independently Controlable Factors
WHY?
기존의 이미지에 대한 Disentangling은 static한 이미지에 대하여 이루어져 왔다. 하지만 강화 학습의 프레임웍에서 에이전트가 환경과 상호작용을 한다면 자신의 행동에 대한 독립적인 변화 요인들을 추출할 수 있을 것이다.
WHAT?
본 논문에서 조종가능한 요소들을 파악하기 위하여 reconstruction term 이외에 selectivity loss를 추가한다. f, g를 encoder, decoder라고 할 때 latent variable의 수 K개 만큼 encoder를 따로 생성한다(f_k). 이와 더불어 K개의 policy또한 생성한다(\pi_k(a|s)). 우리는 특정 policy \pi_k가 오직 그에 상응하는 f_k에만 변화시키도록 유도하고자 한다. sel(s, a, k) = E_{s' \sim P^a_{ss'}}[\frac{|f_k(s') - f_k(s)|}{\Sigma_{k'}|f_{k'}(s') - f_{k'}(s)|}]\\ E_s[\frac{1}{2}\|s-g(f(s))\|^2_2] - \lambda\Sigma_k E_s[\Sigma_a\pi_k(a|s)sel(s, a, k)] 위 식의 앞의 항은 recon loss, 뒤의 항은 disentanglement objective다. 뒤의 항을 최소화 함으로써 특정 정책과 그에 따른 sel(s, a, k)를 최대화한다. 알고리즘은 다음과 같다.  위 접근법의 한계는 우리가 조정할 수 있는 요인의 수에 따라 k가 늘어난다는 점이다. 그래서 각 요인들을 integer대신 embedding을 통하여 indexing하는 방법을 제안한다. 기존의
위 접근법의 한계는 우리가 조정할 수 있는 요인의 수에 따라 k가 늘어난다는 점이다. 그래서 각 요인들을 integer대신 embedding을 통하여 indexing하는 방법을 제안한다. 기존의 \pi_k에 의하여 영향을 받는 요소가 A(h' - h, k) = |h' - h|_k로 측정했다고 한다면 이를 완화하여 k차원의 벡터인 \phi를 사용하여 A(h' - h, \phi) = |h' - h|_{\phi}로 나타낸다. 이를 통하여 한 정책을 통해 변화할 수 있는 여러 요소들을 포괄할 수 있게 된다. 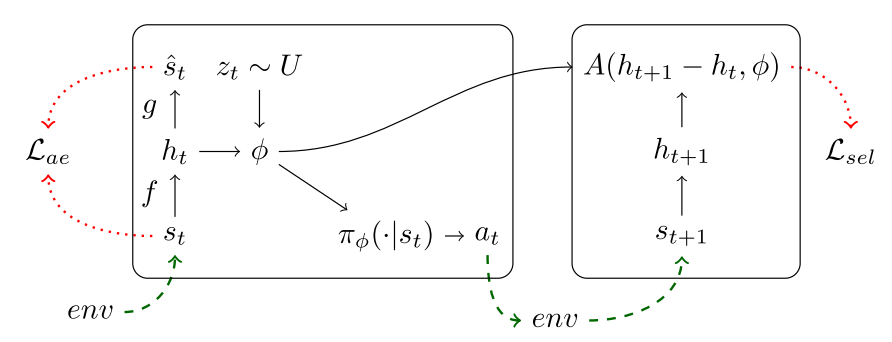
So?
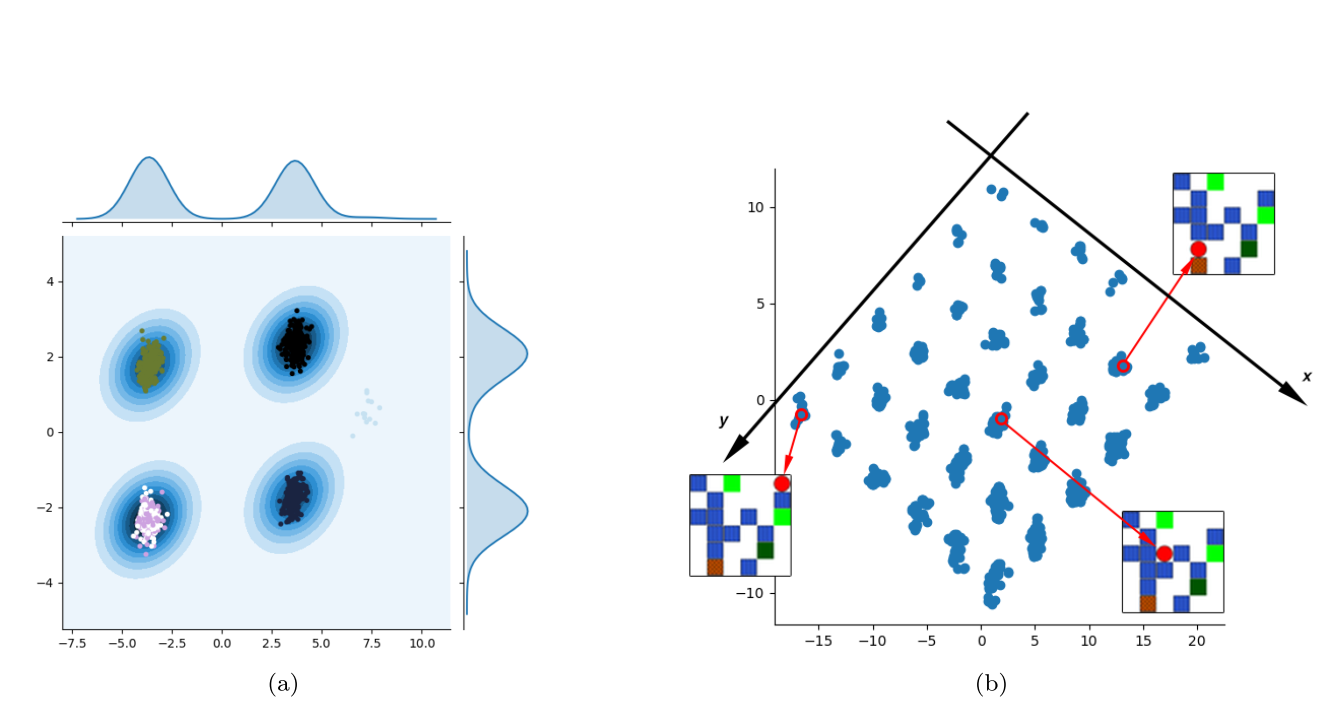 Grid-world, MazeBase와 같은 게임에서 agent의 latent variable들이 변화할 수 있는 요소(agent)의 위치를 확실히 disentangle한 것을 볼 수 있었다.
Grid-world, MazeBase와 같은 게임에서 agent의 latent variable들이 변화할 수 있는 요소(agent)의 위치를 확실히 disentangle한 것을 볼 수 있었다. 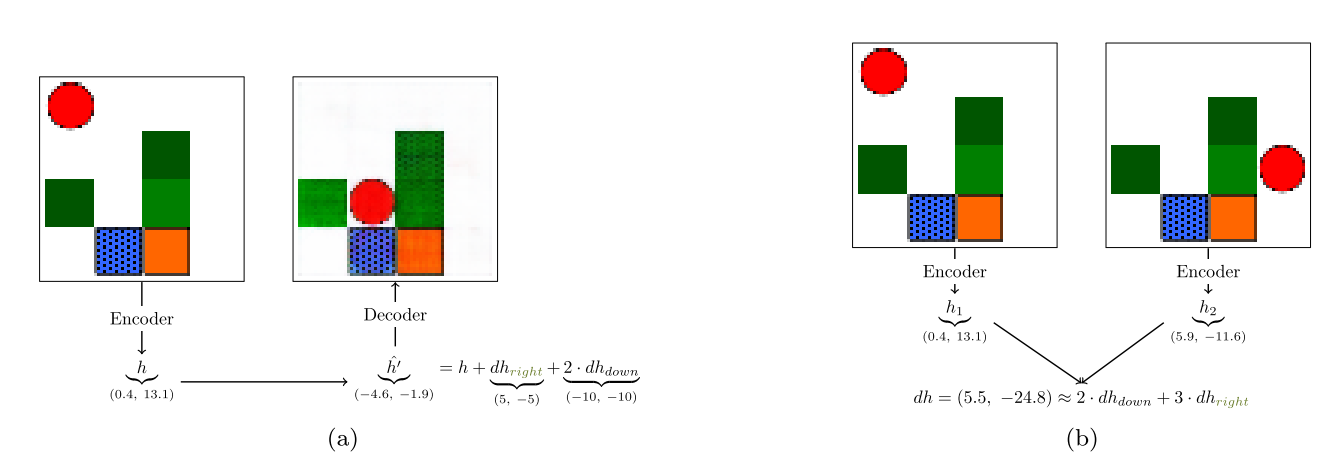 또한 latent space에서 행동 변화를 통하여 state를 예측하거나 state의 변화를 통하여 과거 행동의 변화를 확인하는 것도 가능하였다.
또한 latent space에서 행동 변화를 통하여 state를 예측하거나 state의 변화를 통하여 과거 행동의 변화를 확인하는 것도 가능하였다.
Critic
실험을 보았을 때 distributed embedding인 \phi 64개를 random하게 추출하여 학습한다고 나와있다. \phi를 학습하거나 좀더 체계적으로 선택할 수 있지 않을까?

Rejoice in what you learn and spray it!