Matching Networks for One Shot Learning
in Studies on Deep Learning, Deep Learning
WHY?
현실에서 방대한 데이터와 그에 맞는 label을 구할 수 없기 때문에 몇 가지의 데이터에 대한 label로 좋은 성과를 내는 semi-supervised learning은 중요하다.
WHAT?
Matching network는 few-shot learning을 위하여 주어진 labeled data를 memory처럼 활용한다. 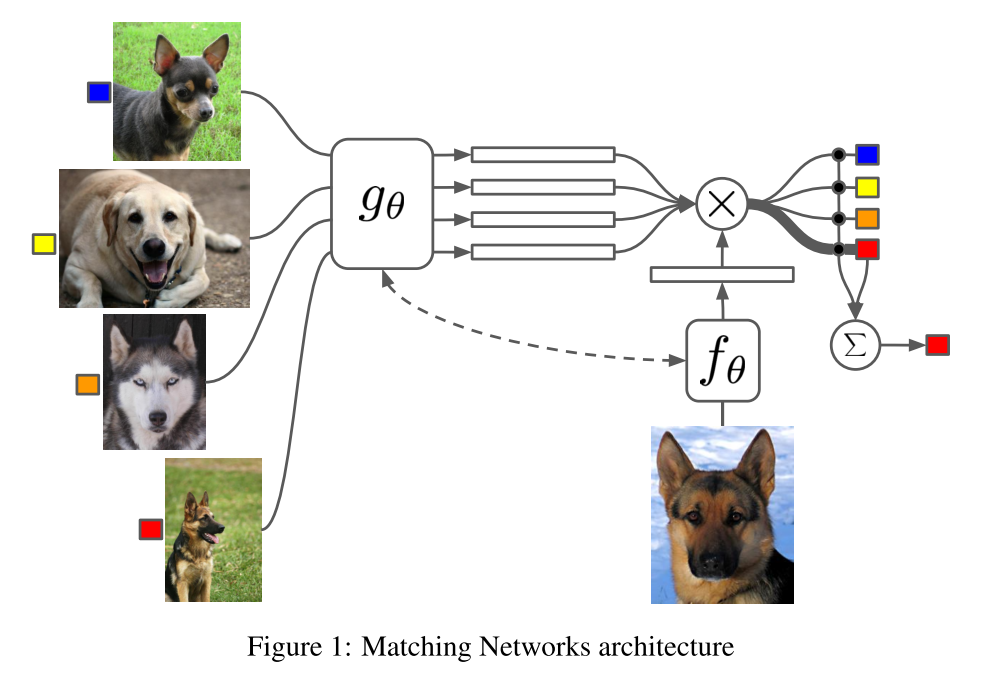 이 메모리를 활용하여 주어진 데이터들과 새로운 데이터의 attention을 통하여 y를 학습한다. 여기서 embedding vector f와 g는 VGG나 Inception같은 deep convolution network를 사용하거나 word embedding을 사용한다. 하지만 g의 경우 주어진 labeled데이터의 context를 반영하는 embedding이 필요하기 때문에 bidirectional LSTM with read-attention을 사용한다.
이 메모리를 활용하여 주어진 데이터들과 새로운 데이터의 attention을 통하여 y를 학습한다. 여기서 embedding vector f와 g는 VGG나 Inception같은 deep convolution network를 사용하거나 word embedding을 사용한다. 하지만 g의 경우 주어진 labeled데이터의 context를 반영하는 embedding이 필요하기 때문에 bidirectional LSTM with read-attention을 사용한다. S \rightarrow c_S(\hat{x})\\ argmax P(y|\hat{x}, S)\\ \hat{y} = \Sigma_{i=1}^k a(\hat{x}, x_i)y_i\\ a(\hat{x}, x_i) = \frac{e^{c(f(\hat{x}), g(x_i))}}{\Sigma_{j=1}^k e^{c(f(\hat{x}), g(x_j))}}\\ f(\hat{x}, S) = attLSTM(f'(\hat{x}, g(S), K)) T는 task에서 주어진 label set이라고 할 때 L는 T의 부분집합이다. 그리고 L에 속하는 support set S와 batch B를 추출하여 S를 참고하여 B를 예측하도록 학습한다.
\theta = argmax_{\theta} E_{L \sim T}[E_{S \sim L, b \sim L} [\Sigma_{(x, y) \in B} log P_{\theta}(y|x, S)]]
이렇게 학습한 모델은 T의 다른 label에 대해서도 좋은 성능을 보인다.
So?
Omniglot, ImageNet의 classification task, Treebank dataset의 One-shot language model task에서 좋은 성능을 보였다.
Critic
external memory와 attention mechanism을 독창적으로 해석한 것 같다. Unsupervised로 이루어 질 수 없다는 점이 아쉽다.

Rejoice in what you learn and spray it!