SCAN: Learning Hierarchical Compositional Visual Concepts
WHY?
실제 세상은 물리나 화학과 같은 몇 가지 일관적인 규칙으로 부터 무한히 다양한 형태가 나온다. 이러한 규칙들은 추상화를 통하여 개념으로 나타날 수 있으며 이러한 개념들의 계층과 조합을 통하여 지수적으로 많은 개념을 만들어낸다.
WHAT?
SCAN(Symbol-Concept Association Network)은 극히 적은 량의 학습으로 disentangled된 요소들에 대하여 개념을 부여하고 추상화한다. 논문에서는 개념을 추상(Abstraction)이라고 제안한다. 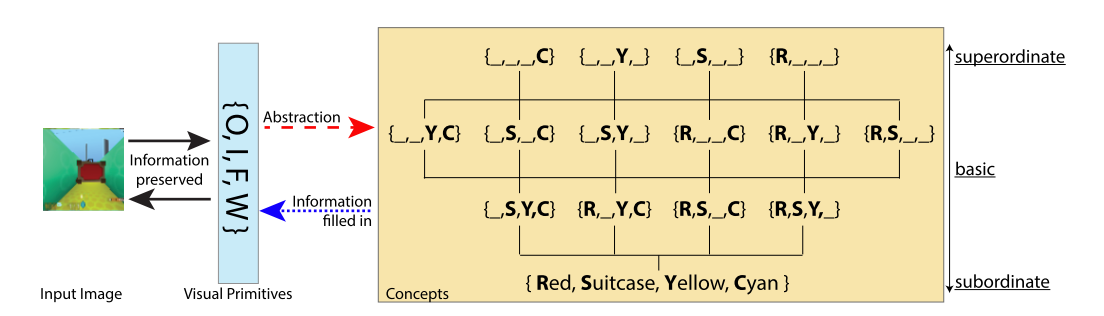 왼쪽 그림에서 네가지 요소(물건 종류, 물건 색, 바닥 색, 벽 색)가 주어졌지만 추상화한다면 오른쪽과 같은 계층으로 나타낼 수 있다. 만약 “여행 가방”이 주어졌다면 주어지지 않은 정보, 즉 물건, 바닥, 벽의 색은 추상화 되며 임의(혹은 각각의 prior)로 채워져야 한다. 또한 이러한 다양한 층위의 개념들 사이에서 관계(super/subordinat, orthogonal)를 나타낼 수 있으며 기초적인 연산(And / In Common / Ignore)을 통하여 새로운 개념을 창출할 수 있다. 우선 데이터로 부터 독립적인 요소를 추출하기 위하여
왼쪽 그림에서 네가지 요소(물건 종류, 물건 색, 바닥 색, 벽 색)가 주어졌지만 추상화한다면 오른쪽과 같은 계층으로 나타낼 수 있다. 만약 “여행 가방”이 주어졌다면 주어지지 않은 정보, 즉 물건, 바닥, 벽의 색은 추상화 되며 임의(혹은 각각의 prior)로 채워져야 한다. 또한 이러한 다양한 층위의 개념들 사이에서 관계(super/subordinat, orthogonal)를 나타낼 수 있으며 기초적인 연산(And / In Common / Ignore)을 통하여 새로운 개념을 창출할 수 있다. 우선 데이터로 부터 독립적인 요소를 추출하기 위하여 \beta-VAE를 사용하는데 이때 사용되는 reconstruction loss term이 데이터에 따라서 치명적인 개념을 놓치는 경우도 있기 때문에 DAE(Denoising Autoencoder)를 사용하여 고차원 개념을 reconstruct하는 목적식을 만든다(C). L_x(\theta, \phi; x, z_x, \beta) = E_{q_{\phi}(z_x | x)}\|J(\hat{x}) - J(x)\|^2_2 - \beta D_{KL}(q_{\phi}(z_x |x)\|p(z_x))\\ \hat{x} \sim p_{\theta}(x | z_x) 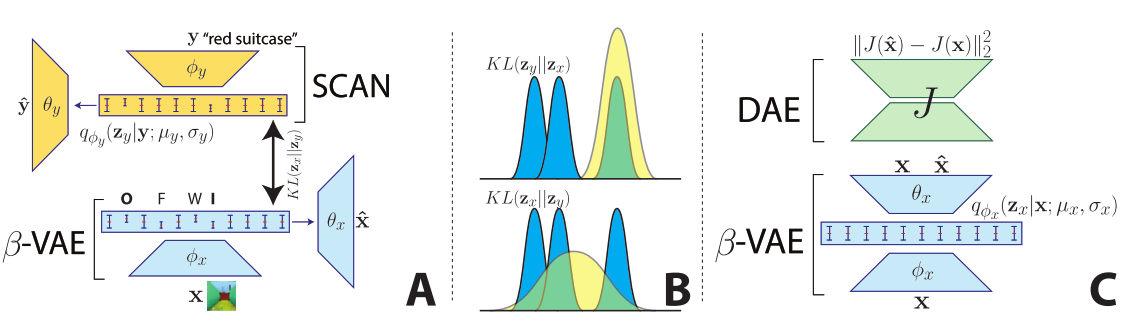 그리고 SCAN은 symbol input을 받아 latent space에 임베딩을 하는데 이 latent space가 위의 학습된 BVAE와 같도록 유도한다(A). 이때 variability가 높은 이미지의 configuration보다 concept이 더 추상화 되어야 하기 때문에 기존에 사용되던
그리고 SCAN은 symbol input을 받아 latent space에 임베딩을 하는데 이 latent space가 위의 학습된 BVAE와 같도록 유도한다(A). 이때 variability가 높은 이미지의 configuration보다 concept이 더 추상화 되어야 하기 때문에 기존에 사용되던 D_{KL}(q(z_y)\|q(z_x))대신 D_{KL}(q(z_x)\|q(z_y))를 사용한다(B). 따라서 목적식은 다음과 같다. L_y(\theta_y, \phi_y; y, x, z_y, \beta, \lambda)\\ = E_{q_{\phi_y}(z_y | y)}[log p_{\theta_y}(y|z_y)] - \beta D_{KL}(q_{\phi_y}(z_y|y)\|p(z_y)) - \lambda D_{KL}(q_{\phi_x}(z_x|x)\|q_{\phi_y}(z_y|y)) 다양한 층위의 개념들로 기초적인 연산을 하기 위하여 추가적인 학습이 필요하다. 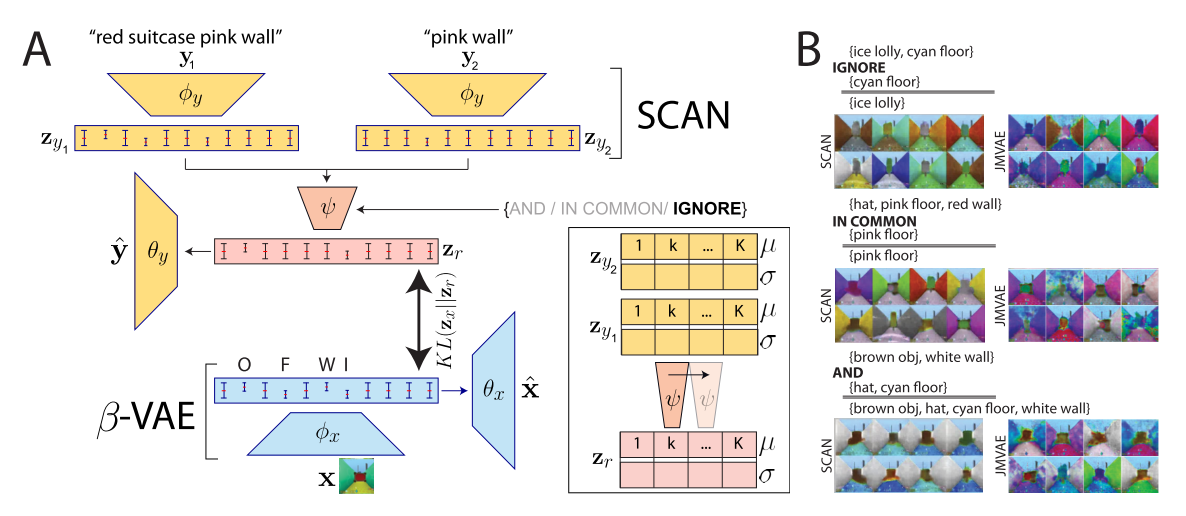 SCAN으로 부터 유추된 두가지의 latent variable과 and, in common, ignore을 나타내는 벡터를 condition한 conditional convolution module을 사용한다.
SCAN으로 부터 유추된 두가지의 latent variable과 and, in common, ignore을 나타내는 벡터를 condition한 conditional convolution module을 사용한다. L_r(\psi; z_x, z_r) = D_{KL}[q_{\phi_x}(z_x|x_i)\|q_{\phi}(z_r|q_{\phi_y}(z_{y_1}|y_1), q_{\phi_y}(z_{y_2}|y_2), r)]
So?
18883가지의 가능한 조합중 133개만 추출하여 각각에 대하여 10가지 예시만 추출하여 학습하였다. 그 결과 학습되지 않은 조합들에 대해서도 symbol을 이미지로 만들거나 이미지로 symbol을 유추하는 작업을 성공적으로 해내었다.
Critic
\beta-VAE에서 추출해낸 가장 일반적인 결과인 x축과 y축의 특성에 대해서는 실험을 하지 않은 것이 아쉽다. CelebA에 적용한 결과를 보았을 때 승능을 좀 더 높여야 할 것 같으며 reconstruction quality가 아쉽다.

Rejoice in what you learn and spray it!