Understanding Disentangling in Beta-VAE
WHY?
\beta-VAE는 최근 disentangling에서 좋은 성과를 거두고 있지만 이에 대하여 깊이있는 이해가 되고 있지는 않다.
WHAT?
\beta-VAE는 Information Bottleneck이론과 밀접하게 연관되어 있다. \beta를 가중치로 패널티를 주는 항은 X와 Z의 정보량이다. \beta-VAE에서는 인코더의 결과인 z를 우리가 정한 prior에 가깝게 만듬으로서 정보를 압축하려한다. 그렇기 때문에 \beta가 작을때는 z가 강한 표현력을 가지고(작은 분산과 떨어진 평균을 갖는 것이 유리하지만 KLD가 너무 커지게 된다) \beta가 클때는 z가 하나의 Gaussian에 근사하여 표현력이 떨어지며 이에 따라 모델의 성능도 하락하게 된다. 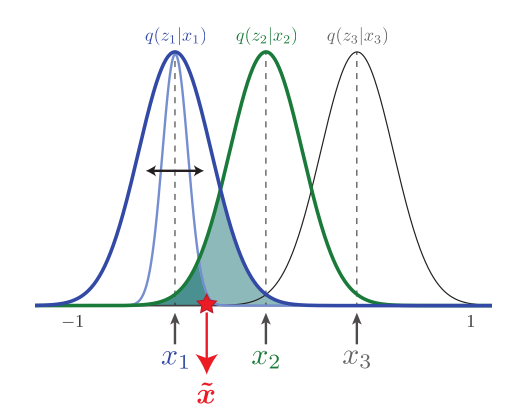
\beta에 큰 값을 줄 때 요소들 간의 Disentangling이 되는 이유는 z의 차원 중 최소한의 z에 연관정보를 모두 담게하여 부득이한 KLD만 가지는 것이 유리하기 때문이다. 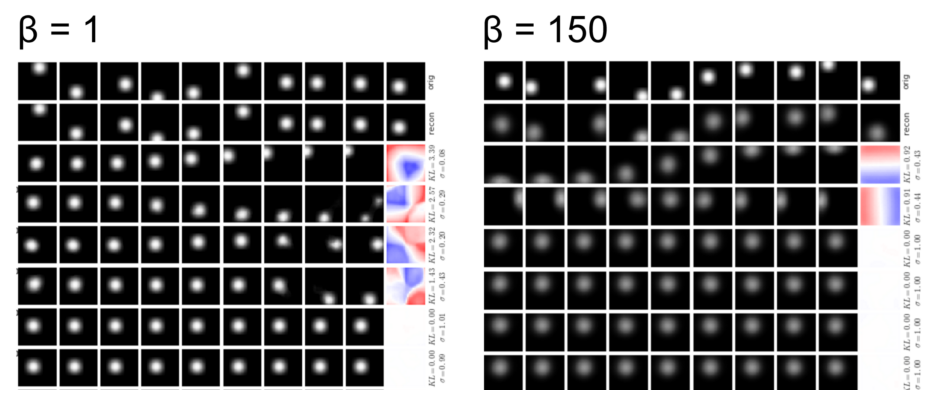 이에 따라 Disentangling되는 순서도 reconstruction과 가장 밀접한 요소(x/y좌표)부터 disentangling이 된다.
이에 따라 Disentangling되는 순서도 reconstruction과 가장 밀접한 요소(x/y좌표)부터 disentangling이 된다. 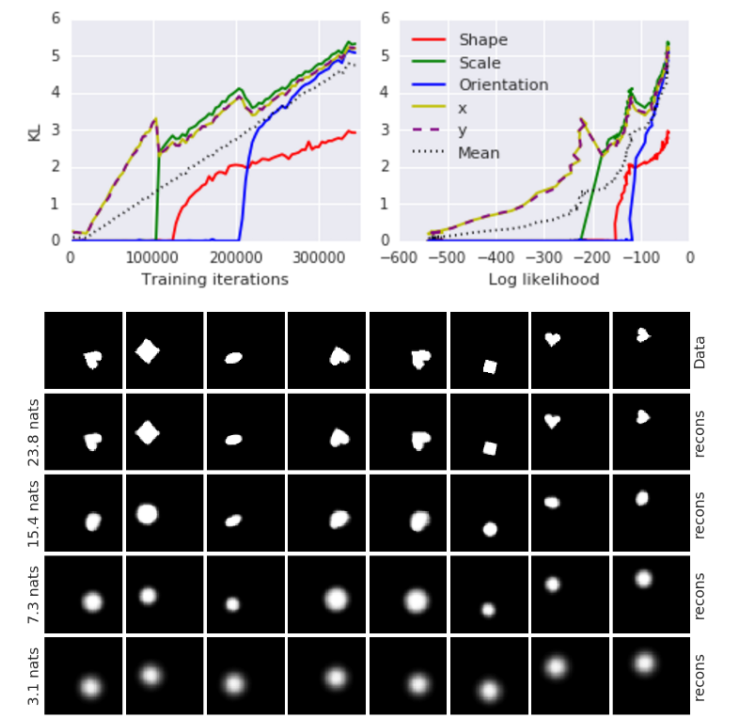
So?
위 사실을 이용하면 KLD에게 capacity C를 줌으로서 표현력을 조정하는 것이 가능하다. 이러한 capacity를 최소한으로부터 점점 늘려가는 방식으로 \beta-VAE에서 reconstruction성능을 크게 떨어뜨리지 않으면서 disentangle하는 것이 가능하다.
Critic
\beta-VAE를 제대로 이해하기 위해서 꼭 이해해야하는 논문이다.

Rejoice in what you learn and spray it!