Deep Convolutional Inverse Graphics Network
WHY?
Image의 representation을 interpretable하게 만든다면 원하는 이미지를 생성해낼 수 있을 것이다.
WHAT?
이를 위하여 Variational Autoencoder모델에 encoder와 decoder를 각각 convolution과 transpose convolution으로 구성하여 학습한다. 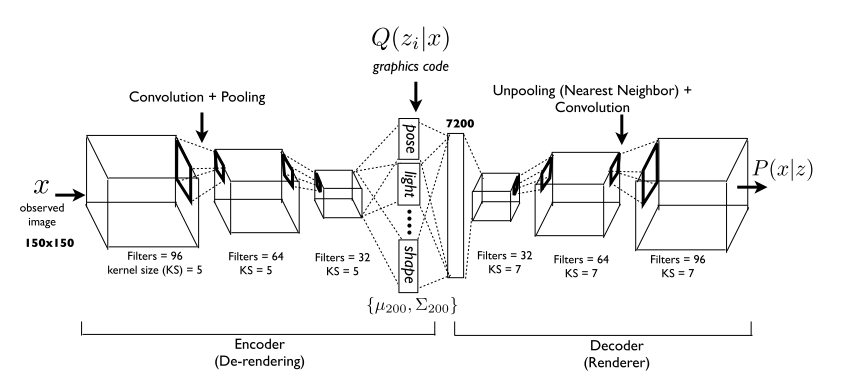 학습 방법은 다음과 같다.
학습 방법은 다음과 같다. 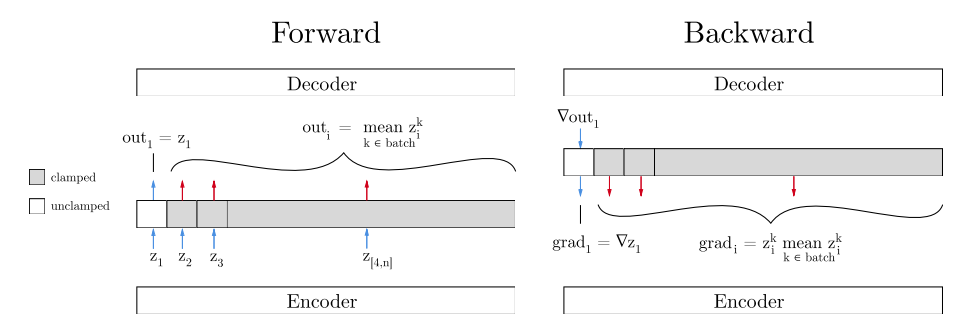
- 우리가 학습하려는 특성에 대응하는
z_{train}을 고른다. - 우리가 학습하려는 특성의 변화만 가지고 있는 데이터로부터 샘플링한다.
- 데이터를 인코더에 통과시켜 z를 구한다.
- 데이터들의 z의 평균을 구한다.
z_{train}이외에 모든 z를 배치의 평균으로 대체하여 디코더에 넣는다(“clamp”)- Reconstruction을 통하여 디코더를 학습시킨다.
z_{train}이외에 모든 z에게는 평균으로 부터의 차이를 gradient로 보낸다.- encoder를 학습시킨다. 이와 같은 방법으로 우리가 학습하려는 z를 돌아가면서 학습한다.
So?
z가 이미지의 특성을 잘 나타낼 뿐만 아니라 원하는 모양의 데이터를 생성해 낼 수 있게 되었다.
Critic
Disentangling의 초창기 논문이라는 점에서 의의가 있다. 하지만 우리가 원하는 variation만을 가진 데이터셋을 구하기 힘들다는 단점이 있다.

Rejoice in what you learn and spray it!