Unsupervised Learning of Disentangled and Interpretable Representations from Sequential Data
WHY?
이미지에 대한 unsupervised disentangling의 시도는 많았지만 오디오와 같은 sequential data에서의 unsupervised disentangling의 시도는 많지 않았다.
WHAT?
Factorized Hierarchical Variational Autoencoder에서는 sequential data를 sequential dependent prior와 sequence independent prior를 가진 hierarchical graphical model로 가정한다. 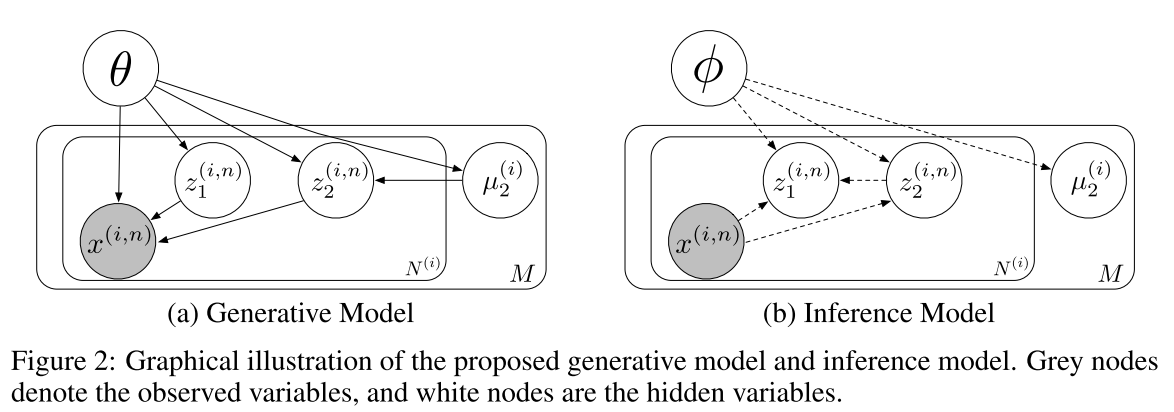 Sequential data이기 때문에 sequence를 나타내는 인덱스 i와 segment를 나타내는 인덱스 n이 존재한다. 한 sequence의 likelihood에 대하여 variational approximation을 하기 위하여 inference model q를 가정하고 variational lowerbound를 구하면 이 식이 각 segment별로 factorized될 수 있다는 것을 알 수 있다.
Sequential data이기 때문에 sequence를 나타내는 인덱스 i와 segment를 나타내는 인덱스 n이 존재한다. 한 sequence의 likelihood에 대하여 variational approximation을 하기 위하여 inference model q를 가정하고 variational lowerbound를 구하면 이 식이 각 segment별로 factorized될 수 있다는 것을 알 수 있다. \mathfrak{L}(\theta, \phi; X) = \Sigma^M_{n=1} \mathfrak{L}(\theta, \phi; \mathbf{x}^{(n)}|\mathbf{\tilde{\mu}}_2) + const \\ \mathfrak{L}(\theta, \phi; \mathbf{x}^{(n)}) = \mathfrak{L}(\theta, \phi; \mathbf{x}^{(n)}|\mathbf{\tilde{\mu}}_2) + \frac{1}{N}log p_{\theta}(\mathbf{\tilde{\mu}}_2) + const 그리하여 sequence에 대한 lowerbound를 각 segment의 conditional segment variational lowerbound를 포함한 segment variational lowerbound를 최대화함으로써 구할 수 있다. 또한 각 sequence에 대하여 \mu_2를 다르게 하기 위하여 다음과 같은 Discriminative object를 추가하여 다음과 같은 목적식(discriminative segment variational lowerbound)이 완성된다. \mathfrak{L}^{dis}(\theta, \phi; \mathbf{x}^{(i, n)}) = \mathfrak(\theta, \phi; \mathbf{x}^{(i, n)}) + \alpha log p(i|\mathbf{z}_2^{(i, n)})\\ log p(i|\mathbf{z}_2^{(i, n)}) := log p_{\theta}(\mathbf{z}_2^{(i, n)}|\mathbf{\tilde{\mu}}_2^{(i)}) - log(\Sigma_{j=1}^{M}p_{\theta}(\mathbf{z}_2^{(i, n)}|\mathbf{\tilde{\mu}}_2^{(j)}) 이와 같은 모델을 학습하기 위하여 sequence to sequence autoencoder model을 구성하여 학습한다. 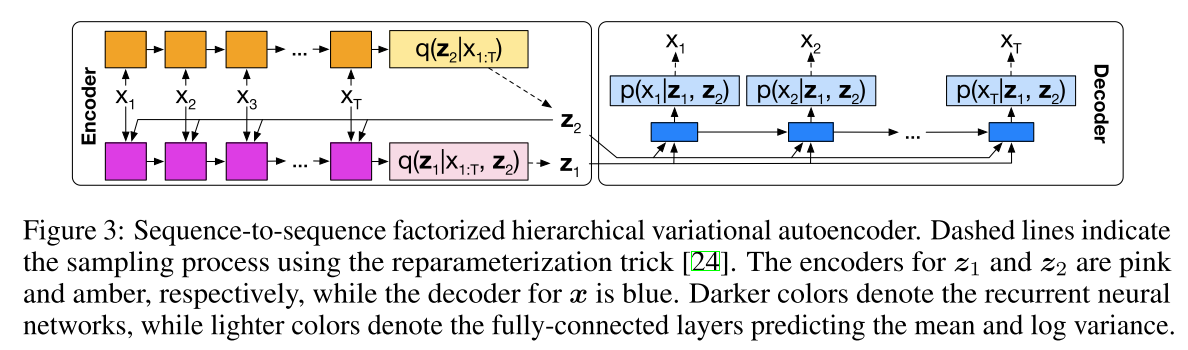
So?
sequential data로부터 unsupervised하게 disentangling하여 오디오에서 음성과 소음/ 남자 음성과 여자 음성의 특징을 분리하여 합성하는 결과를 보였다.
Critic
시연 예제에서 reconstruction의 음질이 아직 자연스럽지 못한 것 같다. 아마 raw audio대신 Mel scale feature bank를 추출하여 사용하여 미세한 손실이 있었던 것 같다. feature를 추출할 수 밖에 없는 이유는 raw audio의 길이가 너무 길어서 각 segment에 대하여 variational inference를 하는 시간이 너무 오래 걸려서 그런 것이 아닌가 싶다. 이와 같은 scalability의 문제는 저자가 후속 논문에서 다루고 있는 것 같다.

Rejoice in what you learn and spray it!