Parallel WaveNet: Fast High-Fidelity Speech Synthesis
WHY?
기존의 WaveNet은 음성 데이터의 학습은 빠른 반면 Sampling(Generation)은 순차적으로 이루어져야 하기 때문에 매우 속도가 느렸다.
Note
Autogregressive Flow와 Inverse Autoregressive flow는 모두 Normalizing Flow를 통하여 Autoregressive구조의 liklihood를 예측한다는 점에서는 같지만 정반대의 특성을 가지고 있다. 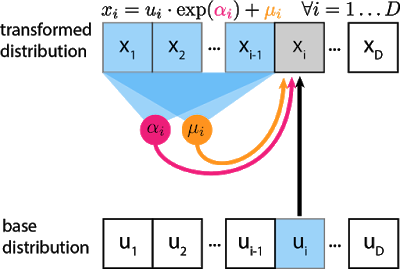
 wavenet이 가진 구조인 AF는 데이터의 학습은 빠르게 이루어지는 반면 Sampling은 느리다. 반면 IAF는 데이터의 학습은 느린 반면 Sampling은 빠르다.
wavenet이 가진 구조인 AF는 데이터의 학습은 빠르게 이루어지는 반면 Sampling은 느리다. 반면 IAF는 데이터의 학습은 느린 반면 Sampling은 빠르다.
WHAT?
Parallel Wavenet은 이 두 가지의 장점을 통합하였다. 우선 데이터를 통하여 하나의 Wavenet을 병렬적으로 빠르게 학습시킨다. 그후, 학습한 Wavenet을 teacher로 사용하여 IAF구조를 가진 student network를 Distilation을 통하여 학습시킨다. 이를 통하여 student network는 noise로 부터 sampling을 하는 방법을 학습할 수 있고 구조의 특성상 빠르게 Generation을 할 수 있게 된다. 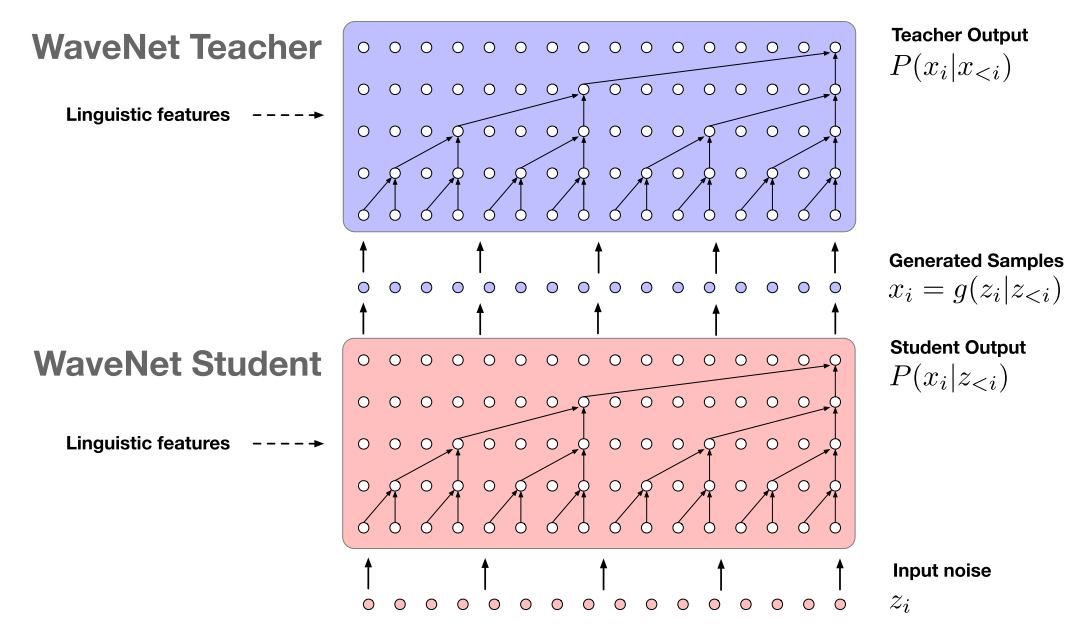
So?
이를 통하여 음성데이터를 기존보다 20배 이상 빠르게 generate할 수 있게 되었다.

Rejoice in what you learn and spray it!