MADE: Masked Autoencoder for Distribution Estimation
WHY?
단순 Autoencoder에서는 x내에 특정 구조를 가정하지 않는다.
WHAT?
MADE에서는 autoencoder에 autoregressive한 구조를 반영하여 generation model을 만들었다. Autoregressive한 구조는 데이터에 특정 순서가 있으며 특정 데이터는 그 이전 데이터로부터만 영향을 받는다고 가정한다. 그러기 위하여 autoencoder의 encoder와 decoder의 weights에 특정 형태의 mask를 씌워 weight의 흐름을 조정한다. \mathbf{h}(\mathbf{x}) = \mathbf{g}(\mathbf{b} + \mathbf{W}\odot\mathbf{M}^\mathbf{W})\mathbf{x})\\ \hat{\mathbf{x}} = sigm(\mathbf{c} + (\mathbf{V}\odot\mathbf{M}^\mathbf{V})\mathbf{h}(\mathbf{x})) 이때 마스크는 다음과 같은 규칙으로 생성한다. m(k)는 1~D-1의 숫자를 복원추출 한 것이며 k번째 노드에 연결될 수 있는 최대의 인풋 개수를 의미한다. M_{k,d}^\mathbf{W} = 1_{m(k)\geq d}\\ M_{d,k}^\mathbf{V} = 1_{d\geq m(k)} 인코더를 여러층 쌓아서 Deep MADE를 만들 수 있다. 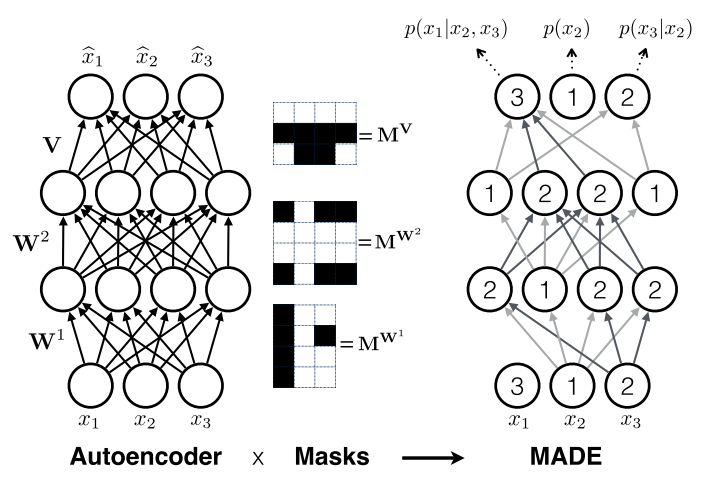 output의 순서는 다소 바뀌지만 모두 conditional distribution으로 바뀌어 있다는 것을 알 수 있다. 알고리즘은 다음과 같다.
output의 순서는 다소 바뀌지만 모두 conditional distribution으로 바뀌어 있다는 것을 알 수 있다. 알고리즘은 다음과 같다. 
So?
autoregressive한 구조의 데이터를 neural net을 통하여 효율적으로 infer할 수 있게 되었다.

Rejoice in what you learn and spray it!