Wavenet: A Generative Model For Raw Audio
WHY?
PixelRNN에서는 LSTM을 활용하여 distribution으로부터 auto-regressive한 구조를 추출할 수 있었다.
WHAT?
Wavenet은 raw audio signal형태로 오디오를 생성하는 모델이다. 기본적으로는 PixelRNN논문에서 제시되었던 PixelCNN의 구조를 차용하였다. mask CNN이 적용되는 여러층의 hiddenlayer를 쌓고 softmax를 통하여 categorical output를 예측하는 모델의 log-liklihood를 최대화한다.
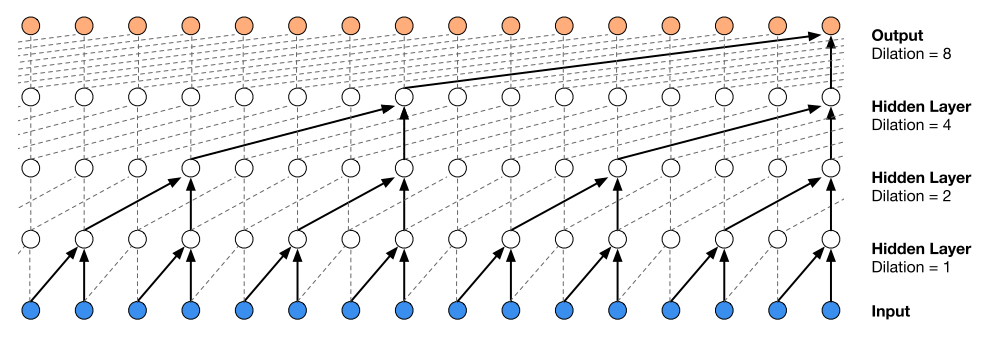 Wavenet에서 적용한 특이한 구조는 dilated causal convolution이다. 기존의 구조에서 receptive field가 hidden layer의 숫자에 대하여 linear하게 증가한다는 한계를 극복하여 exponential하게 증가시키는 구조를 도입하였다. 소프트맥스에서 16-bit integer(65,536)를 예측하는 것을 방지하기 위하여
Wavenet에서 적용한 특이한 구조는 dilated causal convolution이다. 기존의 구조에서 receptive field가 hidden layer의 숫자에 대하여 linear하게 증가한다는 한계를 극복하여 exponential하게 증가시키는 구조를 도입하였다. 소프트맥스에서 16-bit integer(65,536)를 예측하는 것을 방지하기 위하여 \mu-law companding transformation을 도입하여 256개의 값만 예측하도록 조정하였다.
f(x+t) = sign(x_t) \frac{ln(1+\mu\|x_t\|)}{ln(1+\mu)}
또한 Gated activation unit을 사용하였고 pixelrnn에서와 같이 residual and skip connection을 사용하였다.
So?
TTS에서 최고의 성능을 나타내었을 뿐만 아니라 음악 생성, 음성 인식에도 좋은 성과를 보였다.

Rejoice in what you learn and spray it!