Bi-Directional Attention Flow for Machine Comprehension
WHY?
기존 machine comprehension 모델들의 attention은 문맥의 조그마한 부분에 주목하여 문맥을 특정 길이의 벡터로 요약을 하고 어탠션을 단방향적으로, temporal하게 적용하였다. 이러한 기존의 attention 방법은 요약하는 과정에서 정보를 손실하기도 하고 순차적으로 이루어지는 attention간에 의존성이 나타나기 때문에 attention의 역할과 model의 역할이 섞이게 된다.
WHAT?
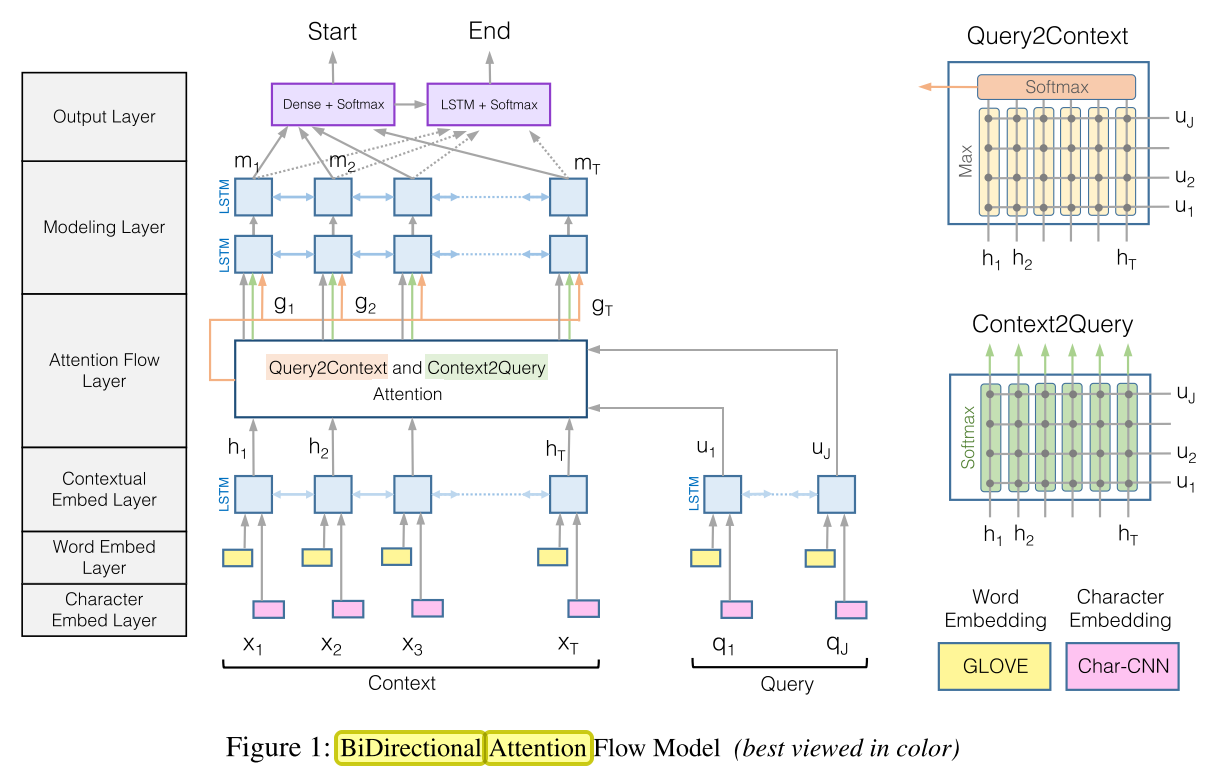 BiDAF모델은 6층으로 이루어진다. 1. Character Embedding Layer에서는 character-level CNN을 통하여 각 단어를 embedding 한다. 2. Word Embedding Layer 에서는 미리 학습시킨 워드 벡터(GLOVE)를 활용하여 각 단어를 embedding 한다. 3. Contextual Embedding Layer에서는 위에서 구한 단어 임베딩을 concatenate 한 후에 context / query 별로 bidirectional-LSTM을 사용하여 문맥적인 정보를 담은 hidden layer인 H(2d * T)와 U(2d * J)를 도출한다. 4. Attention Flow Layer에서는 H에 있는 모든 벡터와 U에 있는 모든 벡터간의 유사도(6d)를 구하여 행렬 S(T * J)를 도출한다. 이 행렬로 두가지 attention을 구한다. 첫번째로 Context-to-query(C2Q) attention은 S를 query에 대해 softmax를 취하여 attention weight를 구한 후 U에 곱하여 attended query vector
BiDAF모델은 6층으로 이루어진다. 1. Character Embedding Layer에서는 character-level CNN을 통하여 각 단어를 embedding 한다. 2. Word Embedding Layer 에서는 미리 학습시킨 워드 벡터(GLOVE)를 활용하여 각 단어를 embedding 한다. 3. Contextual Embedding Layer에서는 위에서 구한 단어 임베딩을 concatenate 한 후에 context / query 별로 bidirectional-LSTM을 사용하여 문맥적인 정보를 담은 hidden layer인 H(2d * T)와 U(2d * J)를 도출한다. 4. Attention Flow Layer에서는 H에 있는 모든 벡터와 U에 있는 모든 벡터간의 유사도(6d)를 구하여 행렬 S(T * J)를 도출한다. 이 행렬로 두가지 attention을 구한다. 첫번째로 Context-to-query(C2Q) attention은 S를 query에 대해 softmax를 취하여 attention weight를 구한 후 U에 곱하여 attended query vector \tilde{U}(2d * T)를 도출한다. 두번째로 Query-to-context(Q2C) attention은 각 단어들에 대하여 query word들과의 유사도의 max를 구한후 softmax를 취하여 attention weight를 구한후 H와 곱하여 attended context vector \tilde{h}(2d)를 도출한다. 마지막으로 H와 \tilde{U}, \tilde{h}의 유사도(8d)를 계산하여 행렬 G(8d * T)를 도출한다. 5. Modeling Layer에서는 G를 활용하여 bidirectional LSTM을 사용하여 행렬 M(2d * T)를 도출한다. 6. Output layer에서는 G와 M을 dense시켜 start index를 구하고 M에 또 한번 bidiretional LSTM사용한 M_2(2d * T)와 G를 dense시켜 end index를 구한다.
So?
SQuAD데이터셋에 대하여 싱글 모델은 R-Net에 버금가는 결과, 앙상블은 최고의 성과를 내었다.

Rejoice in what you learn and spray it!